Zookeeper自然不用我多讲了,一个分布式协调工具。有几个问题我比较好奇:
- Zookeeper如何实现watcher的异步回调? (代码细节)
- Zookeeper的分布式锁如何实现?
- Zookeeper的Queue, barrier等东东怎么玩的?
看了下python版本的ZK客户端kazoo的实现,明白了个大概。
举个简单客户端编程的例子
#!/usr/bin/python
import logging
from time import sleep
from kazoo.client import KazooClient
# print log to console
logging.basicConfig(format='%(levelname)s:%(message)s', level=logging.DEBUG)
zk = KazooClient('127.0.0.1:2181')
zk.start()
def children_callback(children):
print '****' , children
children = zk.get_children('/zookeeper', children_callback)
zk.create('/zookeeper/goodboy')
#zk.delete('/zookeeper/goodboy')
while True: sleep(1)
Kazoo实现异步的大致思路
首先有个前提:每一个Client向服务器发送Request的时候,都会带有一个xid , 每请求一次,xid加1, 同时zk服务端对单个客户端的请求处理士严格按照xid从小到大的顺序来处理并返回。 在这个条件下,客户端每次发送请求之前,先把(request, async_object, xid)这个元组放到一个pending队列里面(其中request包含了请求信息, async_object里面含有回调函数),然后当zk服务端有任何response返回的时候,直接从pending队列中取队首元素就可以完成之前注册的回调函数。
其实更一般的实现是这样的: 客户端发送异步请求时,都在本地存放一个(request,async_object, xid) 元组到map里面。 然后当异步返回response的时候, 根据返回的xid到map里面找出相应的(request, async_objec, xid), 这样就可以执行回调函数了。 鉴于zookeeper处理请求的有序性,所有只用一个pending队列求能轻松搞定。
有几个问题需要考虑:
- 每个API既可以异步调用,又可以同步调用。当然同步调用可用在异步调用的基础上实现。
- 每个Znode上面的Watcher都要采用异步触发的方式实现。
- 不能阻塞主线程,因为主线程要执行上层开发者的代码逻辑。
Kazoo的实现原理(以上述代码片段为例)
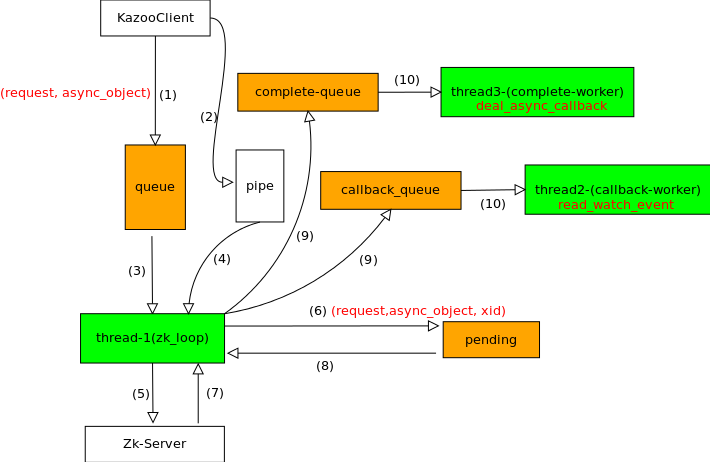
给出几点解释:
2步中, KazooClient的主线程通过os的pipe来做线程间通信。这个还挺有意思的。 主线程会往writepipe里面写一个字节,通知thread_1
3,4步中, thread1是通过 select([socket, readpipe],[],[]) 来检测到socket和readpipe上的读事件的。
- 当socket上有读事件,说明Zookeeper-Server有Response返回。这时候可以去读取socket上的数据。
- 当readpipe上有读事件时,说明主线程又往queue这个队列发送请求了。因为主线程会往queue里放请求,然后往writepipe写字节。
5步中,thread-1将自己Client的Xid自增之后,发送给Zookeeper服务端。就返回了。thread-1自己用了一个While True去不断的探测socket和write_pip上的读事件去了。其实就干上面讲的两步。
7,8步中,发现有socket有数据可读时,就读出response数据。同时和之前6步放入pending队列的request的xid比较一下,必须确认一致才能认为request和response是对上号的。
9,10步中,根据读出的response确定到底是watcher事件还是其他正常API调用。分别走thread-2和thread-3线程。最后异步调用完成。返回结果。
Python-Kazoo的各种奇淫巧技
首先要说明,Zookeeper的各种用法基本都基于一个道理。就是 临时 属性的Znode挂了,Zookeeper服务器会向所有对该Znode父亲加了Watcher的客户端发ChildrenChangeEvent事件。那么这样的话,每个活着的客户端收到ChildrenChangeEvent之后,就可以根据一个统一的算法来默认谁该做什么事情了。比如我们几个客户端都约定好,当我们收到ChildrenChangeEVent事件的时候,当前序列号最小的那哥们去干什么事情。当然其他客户端必须时刻关注序列号最小的哥们现在是不是健在,假设不健在,那大家私底下又要开始下一轮协商了。
Lock
LocK最经典的应用场景当然是高可用了。一个对状态有依赖的服务,当然不能同时开启多个这样的服务,那这时候就可以通过Zookeeper的LOCK来保证任何一个时间点只会有一台机器提供服务。其他的机器都处于阻塞状态。一旦发现提供服务的机器挂了,LOCK就释放了,其他机器会马上去抢锁,抢到锁了, 就可以提供服务了。 这样就能保证服务器在一个zookeeper的SESSION超时时间之内,提供高可用的服务。
Lock的实现,基本就是上面说明的。大家私下选出Leader后,都乖乖让Leader占着锁,其他人默默关注着Leader的父亲(通过exists接口添加Znode的Watch),然后就都阻塞住了。
Semaphore
最多容许N个Client拿到锁。 Kazoo的实现是用的上面的Lock加临时节点。考虑下用注册临时有序节点的方式是否可行呢?
Counter
分布式计数器,N个客户端大家可以并发的同时对counter做自增。Kazoo的实现没有用临时节点,而是采用更简单的思路,直接依赖Znode修改的版本,当大家都拿到同一个版本的znode值做自增时,只有一个会成功(Zookeeper在服务器的版本控制里面做好的),其他都会失败,失败的Client直接重试就OK了。
Barrier
Barrire就是能把所有的N个Client都阻塞住,直到满足某一个条件时,大家都从阻塞状态变成非阻塞状态。 Kazoo实现是:直接往一个节点上通过exists添加watch, 添加watch之后,直接用event阻塞住自己。只有当watch的节点被删除时,event才会释放,主线程从阻塞变成非阻塞。
DoubleBarrier
双层屏障。场景是:必须等所有的Client都加入进来, 才放开阻塞,否则早加入进来的Client会被阻塞住。必须等到所有的Client都离开了,才放开阻塞,否则早离开的Client会被阻塞住。
Party
Party就是一群临时节点的集合。当创建临时节点时,就参加Party, 删除临时节点时,就离开Party。 没什么好讲的。
Queue
分为阻塞队列和非阻塞队列:
- 非阻塞队列实现很容易,就是一个znode下创建一些节点,按照字典序从小到大依次POP给客户端。
- 阻塞队列,容许并发PUT, 但是只能有一个Client在POP。