This article analyzes TokuDB’s index structure—the fractal tree—from an engineering implementation perspective. It describes the on-disk storage layout of ft-index in detail, how ft-index implements point queries, range queries, and insert/delete/update operations, and throughout the discussion attempts a detailed comparison with InnoDB’s B+ tree from multiple angles.
Introduction to the Fractal Tree
The fractal tree is a write-optimized on-disk index data structure. In general, fractal trees offer good write performance (insert/update/delete) while still providing read performance close to that of a B+ tree. According to Percona’s benchmarks, TokuDB’s fractal tree outperforms InnoDB’s B+ tree) on writes, with slightly lower read performance. A similar index structure is the LSM-Tree, but LSM-Trees trade much stronger write performance for weaker read performance.
The most important industrial implementation of the fractal tree is the ft-index (Fractal Tree Index) key-value storage engine developed by Tokutek. Development started in 2007 and the project was open-sourced in 2013; the code is now hosted on GitHub under the GNU General Public License. To fully leverage the ft-index storage engine, Tokutek built a MySQL storage engine plugin on top of the K-V engine that exposes all required APIs—this project is called TokuDB. They also implemented a MongoDB storage engine API; that project is called TokuMX. On April 14, 2015, Percona announced the acquisition of Tokutek, bringing the ft-index/TokuDB/TokuMX product line under Percona’s umbrella. Percona then claimed to be the first vendor offering both MySQL and MongoDB software and solutions.
This article focuses on TokuDB’s ft-index. Compared with a B+ tree, ft-index has several important characteristics:
- From both theoretical complexity and benchmark results, ft-index insert/delete/update performance is better than a B+ tree, but read performance is lower.
- ft-index uses larger index and data pages (4 MB by default for ft-index vs. 16 KB for InnoDB), which yields higher compression ratios for index and data pages. That is, with page compression enabled, inserting the same amount of data consumes less storage with ft-index.
- ft-index supports online DDL (Hot Schema Change). In short, users can continue writing while DDL runs (for example, while adding an index). This capability is a natural consequence of the fractal tree structure. Due to space constraints, this article does not describe Hot Schema Change implementation in detail.
In addition, ft-index supports ACID transactions and MVCC (Multiple Version Concurrency Control), as well as crash recovery.
Because of these properties, Percona claims TokuDB delivers significant performance gains while reducing storage costs for customers.
On-Disk Storage Structure of ft-index
The index structure of ft-index is shown below. For clarity, the binary on-disk layout is simplified and abstracted here; see my blog post for the exact binary format.
In the figure below, gray regions represent a page of the ft-index fractal tree; green regions represent a key; the space between two green regions represents a child pointer. BlockNum is the page offset pointed to by a child pointer. Fanout is the tree’s fanout—the number of child pointers. NodeSize is the number of bytes occupied by a page. NonLeafNode means the current page is a non-leaf node; LeafNode means it is a leaf node. Leaf nodes are the bottom-most nodes that store key-value pairs; non-leaf nodes store keys only, not values. Height denotes tree height: the root has height 3, the next level has height 2, and the bottom leaf level has height 1. Depth denotes tree depth: the root has depth 0, the next level depth 1, and so on.
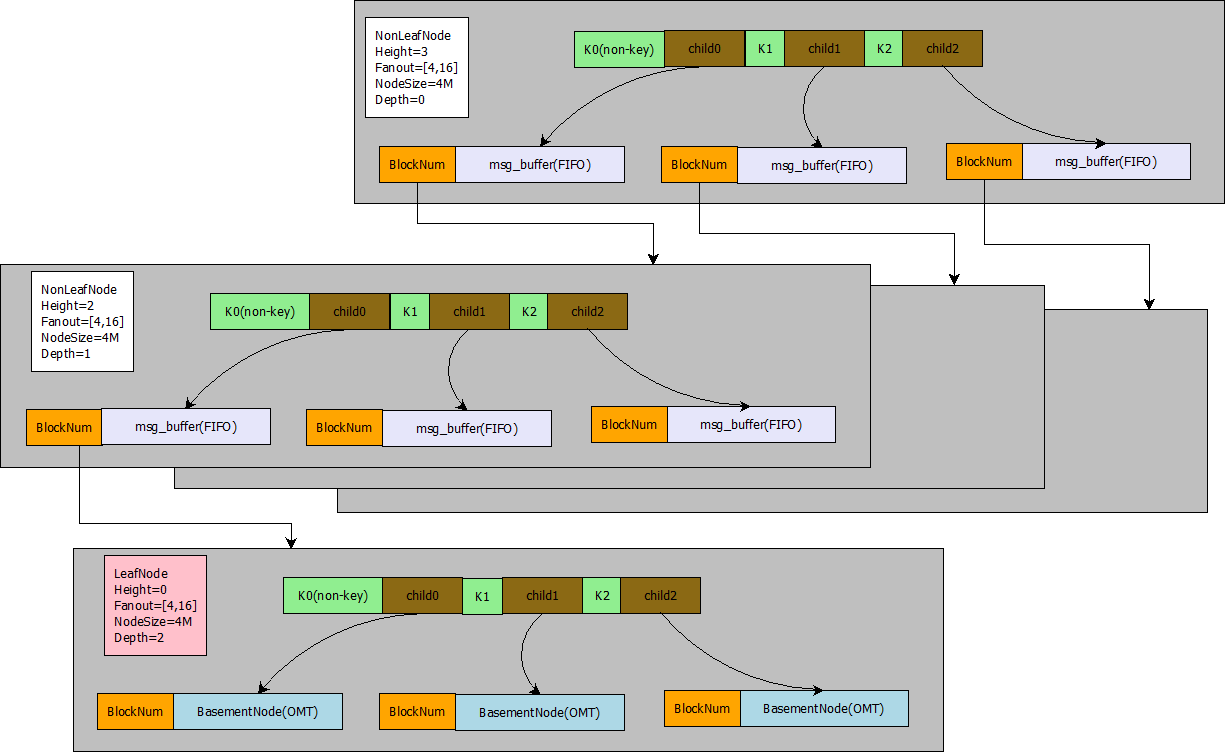
The tree structure of the fractal tree is very similar to a B+ tree. It consists of nodes (called Node or Block; in InnoDB, Page). Each node holds an ordered sequence of keys. Suppose a node’s keys are [3, 8]; then the key sequence partitions the range (-∞, +∞) into three intervals: (-∞, 3), [3, 8), and [8, +∞). Each interval corresponds to one child pointer. In a B+ tree, a child pointer usually points to a page; in a fractal tree, each child pointer points to a node address (BlockNum) and also carries a Message Buffer (msg_buffer). The Message Buffer is a FIFO queue that holds update operations such as insert, delete, update, and HotSchemaChange.
According to the ft-index source code, a more precise description of the fractal tree is:
- A node (block or node; in InnoDB, a page) consists of an ordered sequence of keys. The first key is a null key representing negative infinity.
- There are two node types: leaf nodes and non-leaf nodes. A leaf node’s child pointers point to BasementNodes; a non-leaf node’s child pointers point to ordinary nodes. A BasementNode stores multiple K-V pairs—that is, all lookups must ultimately reach a BasementNode to retrieve a value. This is similar to a B+ tree leaf page: values live in leaf nodes, while non-leaf nodes hold keys for indexing. When a leaf node is loaded into memory, ft-index converts all key-value pairs in the BasementNode into a weakly balanced binary search tree called a scapegoat tree; we will not expand on that here.
- Each key range in a node corresponds to one child pointer. Non-leaf child pointers carry a MessageBuffer, a FIFO queue for insert/delete/update/HotSchemaChange operations. Child pointers and MessageBuffers are serialized and stored in the node’s on-disk file.
- The number of child pointers in each non-leaf node must fall in the range [fanout/4, fanout]. Fanout is a fractal tree parameter (B+ trees have the same concept) used mainly to control tree height. When a non-leaf node’s child count falls below fanout/4, the node is considered too sparse and must be merged with another node (Node Merge), reducing overall tree height. When the count exceeds fanout, the node is too full and must be split (Node Split). These constraints keep the on-disk tree reasonably balanced and bound insert and query complexity.
Note: In the ft-index implementation, balance conditions are more complex. Besides fanout, total node size must stay in [NodeSize/4, NodeSize]; NodeSize is typically 4 MB. When outside that range, corresponding merge or split operations are required.
Insert/Delete/Update in the Fractal Tree
As noted earlier, the fractal tree is write-optimized and offers better write performance than a B+ tree. How does it achieve that?
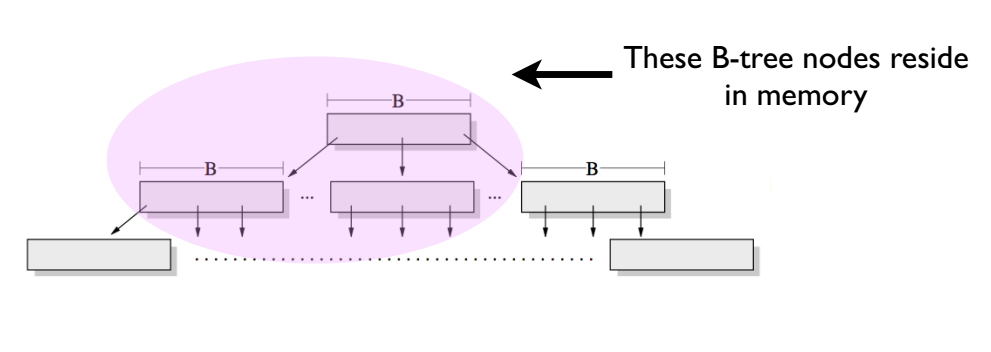
First, “write performance” here means random write performance. For example, suppose we repeatedly run insert into sbtest set x = uuid() on an InnoDB table where x is a unique index column. Because uuid() is random, inserts scatter across many different leaf nodes. In a B+ tree, many such random writes cause a large fraction of hot pages in the LRU cache to sit in the upper levels of the tree (as shown below). Leaf nodes are then less likely to hit the cache, leading to many disk I/Os and a random-write bottleneck. Sequential writes in a B+ tree are fast because they exploit locality of hot data and greatly reduce disk I/O.
Below is the insert flow. For clarity:
a. We use insert as the example, assuming data (Key, Value) is inserted. b. Loading a node (Load Page) always checks whether the node is in the LRU cache first. Only on a cache miss does ft-index use a seed to locate the offset and read the page into memory. c. To focus on the core flow, we temporarily ignore crash logging and transaction handling.
The detailed flow:
- Load the root node.
- Check whether the root needs to split (or merge); if so, split (or merge) the root. Readers interested in root split details can work through that separately.
- When the root has height > 0 (non-leaf), binary search finds the key range containing Key, wrap (Key, Value) as a message (Insert, Key, Value), and place it in the Message Buffer of the child pointer for that range.
- When the root has height = 0 (leaf), apply the message (Insert, Key, Value) to the BasementNode—that is, insert (Key, Value) into the BasementNode.
There is a subtle point: under heavy insert load (random or sequential), the root often becomes full and splits frequently. Splits produce many height-1 nodes; when those fill up, height-2 nodes appear, and the tree grows taller. This behavior hides the secret of better write performance than a B+ tree: each insert returns as soon as it reaches the root, without searching down to the bottom-most BasementNode. Hot data therefore concentrates in the upper levels of the tree (similar to the figure above), exploiting locality and greatly reducing disk I/O.
Update/delete behave similarly to insert, with one important caveat: random read performance of the fractal tree is weaker than InnoDB’s B+ tree (detailed later). Update/delete therefore split into two cases with potentially very different performance:
- Overwriting update/delete: if the key exists, perform update/delete; if it does not, do nothing and do not report an error.
- Strict-match update/delete: if the key exists, update/delete; if it does not, return an error to the caller. This requires checking whether the key exists in a BasementNode first, so point queries drag down update/delete performance.
ft-index also optimizes sequential inserts for better sequential write performance; see sequential write acceleration for details—we omit that here.
Point-Query Implementation in the Fractal Tree
In ft-index, a query like select * from table where id = ? (with an index on id) is a point query; select * from table where id >= ? and id <= ? is a range query. As noted, point-query read performance is weaker than InnoDB’s B+ tree. Below is the point-query flow (assuming the lookup key is Key).
- Load the root and binary-search to find the key range containing Key and the corresponding child pointer.
- Load the node pointed to by that child pointer. If it is non-leaf, continue down the tree until a leaf is reached; if it is a leaf, stop.
After reaching a leaf, we cannot return the BasementNode value directly. Inserts are applied as messages, so all messages on the path from root to leaf must be applied to the leaf’s BasementNode in order. After all messages are applied, look up the value for Key in the BasementNode and return it.
The lookup flow is largely the same as InnoDB’s B+ tree, except the fractal tree must push down message buffers along the path from root to leaf (see the code for push-down details) and apply messages to the BasementNode. Pushing messages during lookup may fill some nodes on the path, but ft-index does not split or merge leaf nodes during queries. The design principle is: insert/update/delete handle node split and merge; select handles lazy push of messages. Updates are therefore deferred to future select operations that apply them to concrete data nodes.
Range-Query Implementation in the Fractal Tree
Range queries in the fractal tree are essentially equivalent to N point queries, with similar cost. Because non-leaf msg_buffers hold pending updates to BasementNodes, each key lookup must walk from root to leaf and apply messages on that path to the BasementNode value. The flow is illustrated below.
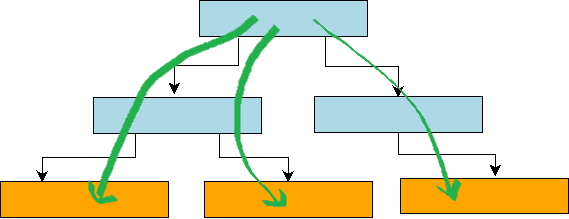
In a B+ tree, leaf nodes are linked in a doubly linked list (see below). We only need to traverse from root to leaf to locate the first key in range, then iterate via next pointers across leaves to read all keys in the range. For B+ tree range queries, only the first positioning requires a root-to-leaf traversal; subsequent reads are largely sequential I/O.
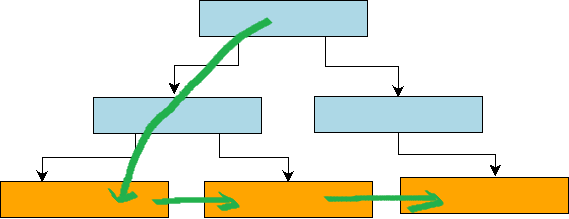
Comparing range-query implementations, the fractal tree’s cost is clearly higher than a B+ tree’s: the fractal tree must traverse the entire subtree under the root covering the range, whereas the B+ tree seeks once to the range start key and then iterates with near-sequential I/O.
Summary
This article used the fractal tree structure as an entry point to describe insert, delete, update, and query operations. Overall, the fractal tree is write-optimized. Its core idea is to buffer updates in per-node MessageBuffers, exploit locality, and turn random writes into sequential writes, greatly improving random-write efficiency. Tokutek’s iiBench results show TokuDB insert (random write) much faster than InnoDB, while select (random read) is somewhat slower but the gap is modest; TokuDB’s 4 MB pages also improve compression. That is why Percona claims higher performance and lower cost.
Online schema change (Hot Schema Change) is also built on MessageBuffer, but unlike insert/delete/update, its message push is broadcast (one message from a parent applies to all children), whereas insert/delete/update use unicast push (one message applies only to the child in the matching key range). The implementation is similar to insert, so we omit further detail.
Finally, welcome discussion from anyone interested in ft-index.
References
- https://github.com/Tokutek/ft-index
- https://en.wikipedia.org/wiki/Fractal_tree_index
- https://www.percona.com/about-percona/newsroom/press-releases/percona-acquires-tokutek
- https://en.wikipedia.org/wiki/Scapegoat_tree
- https://en.wikipedia.org/wiki/Order-maintenance_problem
- Tokutek team’s Fractal Tree slides