本文讲讲TokuDB事务的隔离性,在源码实现中,比较复杂。为了便于描述,本文只对最关键的内容进行描述,对细节的东西略过。
背景介绍
在传统的关系型数据库(例如Oracle, MySQL, SQLServer)中,事务可以说是研发和讨论最核心内容。而事务最核心的性质就是ACID。 其中 A表示事务的原子性,也就是组成事务的所有子任务只有两种结果: 要么随着事务的提交,所有子任务都成功执行;要么随着事务的回滚,所有子任务都撤销。 C表示一致性,也就是无论事务提交或者回滚,都不能破坏数据的一致性约束,这些一致性约束包括键值唯一约束、键值关联关系约束等。I表示隔离性,隔离性一般是针对多个并发事务而言的,也就是在同一个时间点,t1事务和t2事务读取的数据应该是隔离的,这两个事务就好像进了同一酒店的两间房间一样,各自在各自的房间里面活动,他们相互之间并不能看到各自在干嘛。D表示持久性,这个性质保证了一个事务一旦承诺用户成功提交,那么即便是后继数据库进程crash或者操作系统crash,只要磁盘数据没坏,那么下次启动数据库后,这个事务的执行结果仍然可以读取到。
TokuDB目前完全支持事务的ACID。 从实现上看, 由于TokuDB采用的分形树作为索引,而InnoDB采用B+树作为索引结构,因而TokuDB在事务的实现上和InnoDB有很大不同。 本文主要讲讲TokuDB的事务隔离性的实现,也就是常提到的多版本并发控制(MVCC)。在InnoDB中, 设计了redo和undo两种日志,redo存放页的物理修改日志,用来保证事务的持久性; undo存放事务的逻辑修改日志,它实际存放了一条记录在多个并发事务下的多个版本,用来实现事务的隔离性(MVCC)和回滚操作。
由于TokuDB的分形树采用消息传递的方式来做增删改更新操作,一条消息就是事务对该记录修改的一个版本,因此,在TokuDB源码实现中,并没有额外的undo-log的概念和实现,取而代之的是一条记录多条消息的管理机制。虽然一条记录多条消息的方式可以实现事务的MVCC,却无法解决事务回滚的问题,因此TokuDB额外设计了tokudb.rollback这个日志文件来做帮助实现事务回滚。
TokuDB的事务表示
在tokudb中, 在用户执行的一个事务,具体到存储引擎层面会被拆开成许多个小事务(这种小事务记为txn)。 例如用户执行这样一个事务:
begin;
insert into hello set id = 1, value = '1';
commit;
对应到TokuDB存储引擎的redo-log中的记录为:
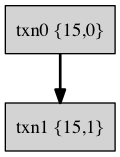
xbegin 'b': lsn=236599 xid=15,0 parentxid=0,0 crc=29e4d0a1 len=53
xbegin 'b': lsn=236600 xid=15,1 parentxid=15,0 crc=282cb1a1 len=53
enq_insert 'I': lsn=236601 filenum=13 xid=15,1 key={...} value={...} crc=a42128e5 len=58
xcommit 'C': lsn=236602 xid=15,1 crc=ec9bba3d len=37
xprepare 'P': lsn=236603 xid=15,0 xa_xid={...} crc=db091de4 len=67
xcommit 'C': lsn=236604 xid=15,0 crc=ec997b3d len=37
对应的事务树如下图所示:
对一个较为复杂一点,带有savepoint的事务例子:
begin;
insert into hello set id = 2, value = '2' ;
savepoint mark1;
insert into hello set id = 3, value = '3' ;
savepoint mark2;
commit;
对应的redo-log的记录为
xbegin 'b': lsn=236669 xid=17,0 parentxid=0,0 crc=c01888a6 len=53
xbegin 'b': lsn=236670 xid=17,1 parentxid=17,0 crc=cf400ba6 len=53
enq_insert 'I': lsn=236671 filenum=13 xid=17,1 key={...} value={...} crc=8ce371e3 len=58
xcommit 'C': lsn=236672 xid=17,1 crc=ec4a923d len=37
xbegin 'b': lsn=236673 xid=17,2 parentxid=17,0 crc=cb7c6fa6 len=53
xbegin 'b': lsn=236674 xid=17,3 parentxid=17,2 crc=c9a4c3a6 len=53
enq_insert 'I': lsn=236675 filenum=13 xid=17,3 key={...} value={...} crc=641148e2 len=58
xcommit 'C': lsn=236676 xid=17,3 crc=ec4e143d len=37
xcommit 'C': lsn=236677 xid=17,2 crc=ec4cf43d len=37
xprepare 'P': lsn=236678 xid=17,0 xa_xid={...} crc=76e302b4 len=67
xcommit 'C': lsn=236679 xid=17,0 crc=ec42b43d len=37
这个事务组成的一棵事务树如下图所示:
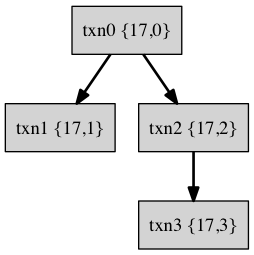
在tokudb中,使用{parent_id, child_id}这样一个二元组来记录一个txn和其他txn的依赖关系。这样从根事务到叶子几点的一组标号就可以唯一标示一个txn, 这一组标号列表称之为xids, xids我认为也可以称为事务号。 例如txn3的xids = {17, 2, 3 } , txn2的xids = {17, 2}, txn1的xids= {17, 1}, txn0的xids = {17, 0}。
于是对于事务中的每一个操作(xbegin/xcommit/enq_insert/xprepare),都有一个xids来标识这个操作所在的事务号。 TokuDB中的每一条消息(insert/delete/update消息)都会携带这样一个xids事务号。这个xids事务号,在TokuDB的实现中扮演这非常重要的角色,与之相关的功能也特别复杂。
事务管理器
事务管理器用来管理TokuDB存储引擎所有事务集合, 它主要维护着这几个信息:
- 活跃事务列表。活跃事务列表只会记录root事务,因为根据root事务其实可以找到整棵事务树的所有child事务。 这个事务列表保存这当前时间点已经开始,但是尚未结束的所有root事务。
- 镜像读事务列表(snapshot read transaction)。
- 活跃事务的引用列表(referenced_xids)。这个概念有点不好理解,假设一个活跃事务开始(xbegin)时间点为begin_id, 提交(xcommit)的时间点为end_id。那么referenced_xids就是维护(begin_id, end_id)这样一个二元组,这个二元组的用处就是可以找到一个事务的整个生命周期的所有活跃事务,用处主要是用来做后文说到的full gc操作。
分形树LeafEntry
在之前博客中,已经介绍了分形树的树形结构。其中说到,在做insert/delete/update这样的操作时,会把从root到leaf的所有消息都apply到LeafNode节点中。 为了后面详细描述apply的过程,先介绍下LeafNode的存储结构。
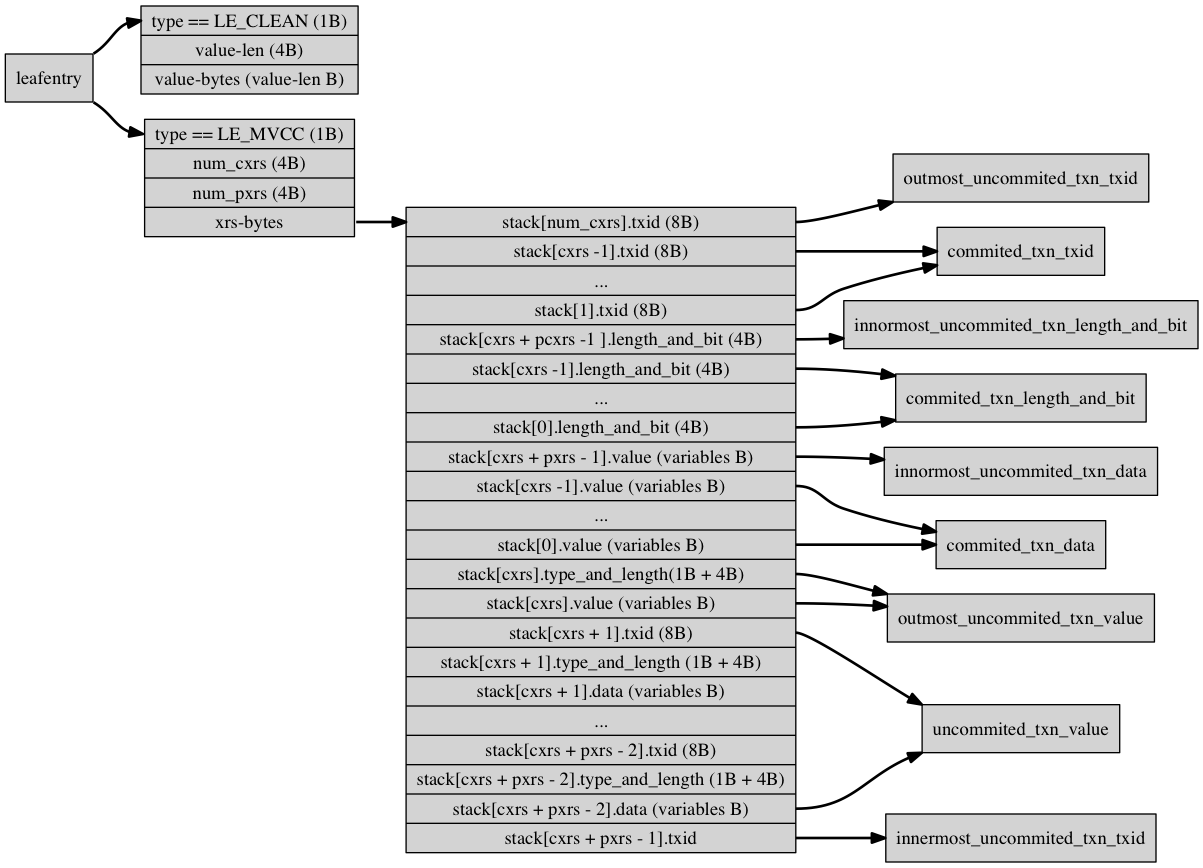
leafNode简单来说,就是由多个leafEntry组成,每个leafEntry就是一个{k, v1, v2, … }这样的键值对, 其中v1, v2 .. 表示一个key对应的值的多个版本。leafNode的详细布局参考这里。具体到一个key对应得leafEntry的结构详细如下图所示。
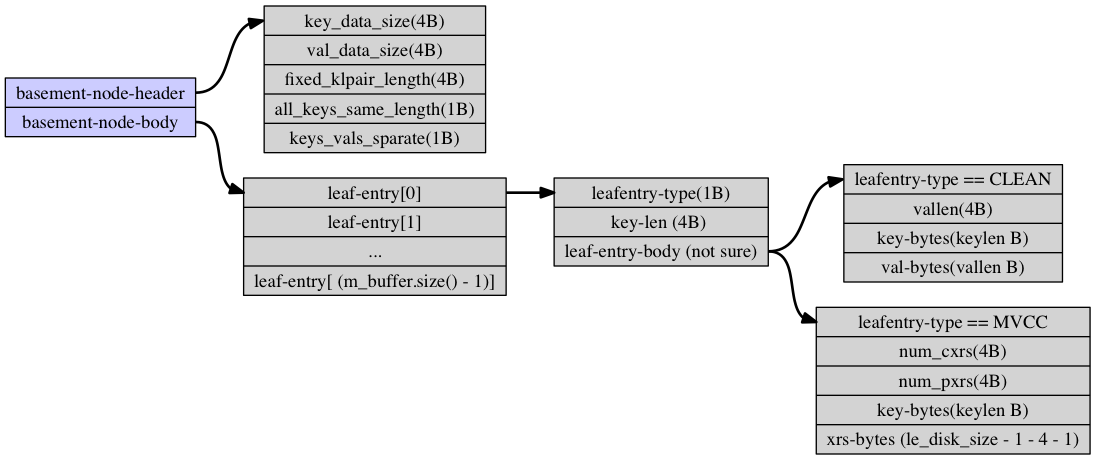{kind=link}
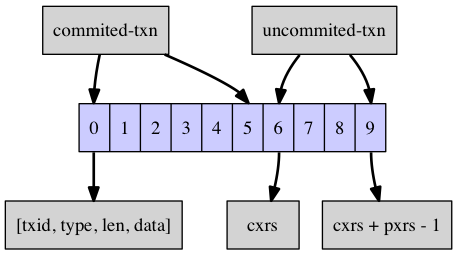
由上图看出,一个leafEntry其实就是一个栈, 这个栈底部[0~5]这一段表示已经提交(commited transaction)的事务的Value值。栈的顶部[6~9]这一段表示当前尚未提交的活跃事务(uncommited transaction)。 栈中存放的单个元素为(txid, type, len, data)这样一个四元组,表明了这个事务对应的value取值。更通用一点讲,[0, cxrs-1]这一段栈表示已经提交的事务,本来已经提交的事务不应存在于栈中,但之所以存在,就是因为有其他事务通过snapshot read的方式引用了这些事务,因此,除非所有引用[0, cxrs-1]这段事务的所有事务都提交,否则[0, cxrs-1]这段栈的事务就不会被回收(参见后文的【多版本记录回收】)。[cxrs, cxrs+pxrs-1]这一段栈表示当前活跃的尚未提交的事务列表,当这部分事务提交时,cxrs会往后移动,最终到栈顶。
MVCC实现
写入操作
这里我们认为写入操作包括三种,分别为insert / delete / commit 三种类型。
对于insert和delete这两种类型的写入操作,只需要在LeafEntry的栈顶放置一个元素即可。 如下图所示:
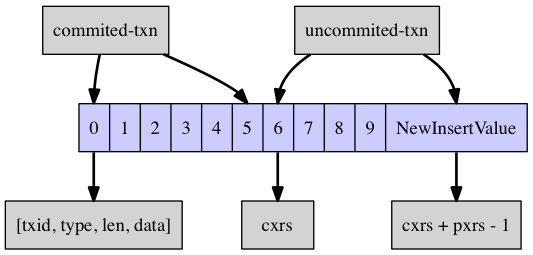
对于commit操作,只需把LeafEntry的栈顶元素放到cxrs这个指针处,然后收缩栈顶指针即可。如下图所示:
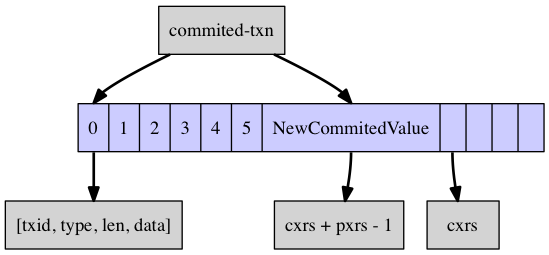
这样,就维护好了写入操作的多版本操作。当然, 具体到代码实现时,还有很多很多的细节需要处理,也有很多的优化点。比如ule_do_implicit_promotions。
读取操作
对读取操作而言, 数据库一般支持多个隔离级别。MySQL的InnoDB支持Read UnCommitted(RU)、Read REPEATABLE(RR)、Read Commited(RC)、SERIALIZABLE(S)。其中RU存在脏读的情况(脏读指读取到未提交的事务), RC/RR/RU存在幻读的情况(幻读一般指一个事务在更新时可能会更新到其他事务已经提交的记录)。
TokuDB同样支持上述4中隔离级别, 在源码实现时, ft-index将事务的读取操作按照事务隔离级别分成3类:
- TXN_SNAPSHOT_NONE : 这类不需要snapshot read, SERIALIZABLE和Read Uncommited两个隔离级别属于这一类。
- TXN_SNAPSHOT_ROOT : Read REPEATABLE隔离级别属于这类。在这种其情况下, 说明事务只需要读取到root事务对应的xid之前已经提交的记录即可。
- TXN_SNAPSHOT_CHILD: READ COMMITTED属于这类。在这种情况下,儿子事务A需要根据自己事务的xid来找到snapshot读的版本,因为在这个事务A开启时,可能有其他事务B做了更新,并提交,那么事务A必须读取B更新之后的结果。
多版本记录回收
随着时间的推移,越来越多的老事务被提交,新事务开始执行。 在分形树中的LeafNode中commited的事务数量会越来越多,假设不想方设法把这些过期的事务记录清理掉的话,会造成BasementNode节点占用大量空间,也会造成TokuDB的数据文件存放大量无用的数据。 在TokuDB中, 清理这些过期事务的操作称之为垃圾回收(Garbage Collection)。 其实InnoDB也存在过期事务回收这么一个过程,InnoDB的同一个Key的多个版本的Value存放在undo log 页上, 当事务过期时, 后台有一个purge线程专门来复杂清理这些过期的事务,从而腾出undo log页给后面的事务使用, 这样可以控制undo log无限增长。
TokuDB存储引擎中没有类似于 InnoDB的purge线程来负责清理过期事务,因为过期事务的清理都是在执行更新操作是顺便GC的。 也就是在Insert/Delete/Update这些操作执行时,都会判断以下当前的LeafEntry是否满足GC的条件, 若满足GC条件时,就删除LeafEntry中过期的事务, 重新整理LeafEntry 的内存空间。按照TokuDB源码的实现,GC分为两种类型:
Simple GC
在每次apply 消息到leafentry 时, 都会携带一个gc_info, 这个gc_info 中包含了oldest_referenced_xid这个字段。 那么simple_gc的意思是什么呢? simple_gc就是做一次简单的GC, 直接把commited的事务列表清理掉(记住要剩下一个commit事务的记录, 否则下次查找这条commited的记录怎么找的到? )。这就是simple_gc, 简单暴力高效。
Full GC
full gc的触发条件和gc流程都比较复杂, 根本意图都是要清理掉过期的已经提交的事务。这里不再展开。
总结
本文大致介绍了TokuDB事务的隔离性实现原理, 包括TokuDB的事务表示、分形树的LeafEntry的结构、MVCC的实现流程、多版本记录回收方式这些方面的内容。 TokuDB之所有没有undo log,就是因为分形树中的更新消息本身就记录了事务的记录版本。另外, TokuDB的过期事务回收也不需要像InnoDB那样专门开启一个后台线程异步回收,而是才用在更新操作执行的过程中分摊回收。总之,由于TokuDB基于分形树之上实现事务,因而各方面的思路都有大的差异,这也是TokuDB团队的创新吧。
最后,欢迎对ft-index感兴趣的同学一起交流讨论。 我的工作和ft-index并没有什么交集,完全是个人兴趣和好奇心驱使,才去看看ft-index的实现,在翻代码过程中,也为偶尔能领略到ft-index的一点点技艺之美而欣喜。
{kind=link}