HBaseCon West 2017的PPT解读如下:
1. HBase at Xiaomi
由小米的杨哲和张洸濠合作分享,两位是2016年新晋升的HBase Committer (ps: 小米目前总共产生了8位HBase Committer,其中2位HBase PMC,解决了数百个issue). 分享的一些亮点主要有:
1. 0.94升级到0.98集群的一些经验。
2. 小米内部HBase使用g1gc的一些经验。
3. 2016年小米对社区做的一些开发和改进,包括但不限于顺序推送复制日志/优化Scan操作/开发异步客户端功能以及相关测试结果,等等。
2. Apache HBase at DiDi (by Kang Yuan)
主要分享了HBase在滴滴的一些实践经验,目前滴滴的HBase是基于0.98.21版本,然后将rsgroup这个功能迁移到了自己的分支,用来做业务隔离。另外,PPT中也提到通过将地理位置坐标进行GeoHash转换成一维byte存放到HBase中,可以解决查询一个点周边坐标的问题。
3. Accordion: HBase Breathes with In-Memory Compaction (From Yahoo)
有了InMemory-Compaction功能之后,HBase支持将Memstore直接Flush成一个ImmutableSegment,这个ImmutableSegment其实是一块内存空间,多次Memstore的Flush操作会导致产生多个ImmutableSegment,特定条件下,多个ImmtableSegment会进行In-Memory的Compaction,也就是多个ImmutableSegment完全在内存中合并成为一个大的ImmutableSegment(其中BASIC类型的InMemoryCompaction会保留所有数据,EAGER类型的InMemoryCompaction会清理冗余版本数据)。最终,这个大的ImmutableSegment还是要Flush到磁盘的,然后接着触发做磁盘上的Compaction操作。
按照设计文档以及PPT的说明,InMemory-Compaction有以下好处:
- 由于InMemoryCompaction会在内存中进行compaction, 不用频繁的Flush Memstore到Disk(Flush次数太多会造成storefile个数增长, storefile的增长会导致读性能严重下降), 从而可以降低读操作延迟。
- ImmtableSegment今后可能会和HFile的layout保持一致,这样Flush的速度将大幅提升。
- 对于行数据频繁更新的场景,InMemory-Compaction可以采用EAGER方式在内存中就清理掉冗余版本数据,节省了这部分数据落盘的代价。
最后,PPT测试数据也确实说明使用InMemoryCompaction后,写吞吐有较大幅度提升,读延迟有较大幅度下降。
ps. In-memory Compaction由stack等6位成员共同完成(将在HBase2.0的release版本发布),这其中有两位美女工程师(PPT中的照片证明颜值确实很高),现在都已经是HBase的Committer了。 另外,In-memory compaction详细设计文档请参考:https://issues.apache.org/jira/browse/HBASE-13408
4. Efficient and portable data processing with Apache Beam and HBase (By Google)
这个演讲更多是来HBaseCon宣传下Apache Beam这个项目。 Apache Beam这个项目始于2016年2月份,近1年多的时间内就收到了来自全球178个贡献者的8600+提交,主要是希望提供一个统一的API用来同时处理Batch任务和Streaming任务,他的API后端可以接Apex/Flink/Spark/GoogleCloudDataFlow等服务,同时提供Java和Python的客户端SDK。这个东西就好比JDBC一样,提供了一个统一的借口,后端可以连接MySQL/Oracle/Postgresql/SQLServer等关系型数据库。我没理解错的话,这个东西应该是可以用来在HBase/MongoDB/HDFS/Cassandra/Kafka/BigTable/Spanner/Elasticsearch/GridFS/Hive/AMQP等(超过20种通用的存储服务)各种服务间实现数据transform。
5. Data Product at Airbnb
来自Airbnb的这份演讲,主要介绍了Airbnb内部HBase的应用场景,以及如何实现统一执行batch任务和streaming任务。
6. Democratizing HBase(by Hortonworks)
作者Josh Elser是来自Hortonworks的工程师,也是HBase Committer,他参与了多个Apache的顶级项目,例如HBase/Phoenix等等。演讲主要介绍了目前HBase在多租户资源隔离方面的一些工作,主要包括安全认证,RPC Quotas,Rpc优先级,Space Quotas,RegionServer Group等内容。
7. Apache Spark – Apache HBase Connector Feature Rich and Efficient Access to HBase through Spark SQL (by Hortonworks)
介绍Hortonworks开源的SHC项目相关内容。
8. Gohbase: Pure Go HBase Client(by Arista Networks)
一般非Java语言(Python/Golang/Javascript)会采用Thrift协议生成各自语言的SDK, SDK先访问HBase的Thrift server,然后thrift server后端通过Java Native Client连RS/Master,通过ThriftServer中转来实现通信,但通过thrift协议生成的非Java版本的客户端接口比较原始,不是特别好用,另外早期的ThriftServer bug也比较多。
因此,演讲者基于HBase的Protobuf协议,实现了一套纯Golang写的hbase client,其实相当于说把Java Native Client的逻辑全部用Golang写了一遍。使用体验应该要比其他Golang语言写的SDK好用。性能上,Gohbase某些场景下甚至优于Java的客户端。
最后,作者在开发Gohbase的过程中,发现了HBASE-18066这个bug, 这个bug目前已经由小米openinx修复。这个bug的问题在于:设置closestRowBefore为true的Get操作,在RegionServer端的代码实现中,是先通过不带mvcc的方式拿到rowKey, 然后再通过带mvcc的方式去找这个rowKey对应的Value, 并返回。由于前者不带mvcc, 后者带mvcc,所以导致拿到的数据可能不一致。修复方式就是把这类操作都由reversed scan来实现,由于scan操作统一设了mvcc,也就解决了这个BUG。
9. Analyzing Cryptocurrencies on HBase For Finance, Forensics, and Fraud (by Ripple)
Ripple是一种有点类似Bitcoin的加密数字货币,背后应该是有Ripple这个商业公司在支撑,这份演讲主要介绍了Ripple现状以及HBase在公司内部的应用场景,重点应该还是Ripple的相关业务介绍。
10. Splice Machine: Powering Hybrid Applications (by Splice Machine)
Splice Machine是一家做数据库(DAAS)云服务的厂商,PPT主要是演示了一遍他们的Hadoop相关云产品使用过程,对HBase云产品形态感兴趣的同学可以看一下。本次分享主要还是推广他们的产品。
11. OpenTSDB: 2.4 and 3.0 update(by Yahoo)
作者是一位维护OpenTSDB近4年的程序员,干货比较多。OpenTSDB是一款基于HBase之上开发的时间序列数据库产品,能方便的实现水平扩展。具体到HBase的存储时,OpenTSDB设计的RowKey为
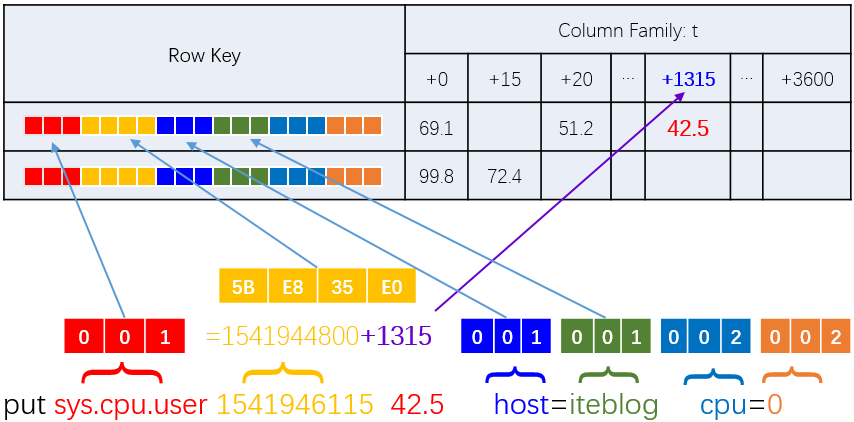
这样的RowKey设计,可以满足用户根据metric + ts + 若干个tag组合进行查询,用SQL来表达就是
select * from table where metric=? and ts < ? and ts > ? and (tag_i= ?) and (tag_j= ?)
注意,如果一个查询的时间跨度较大,例如查24小时的监控数据。那么,这24小时的数据会分散在24个不同的行上,也就是说需要进行24次Seek+Read操作才能读取到完整的监控数据。因此,长跨度的查询必须在损失精度的情况下抽样,才能保证较好的性能。
HBASE-15181 实现了DateTieredCompaction。DateTieredCompaction的策略是按照时间轴(一般待合并区间为[now - maxAge, now], 其中maxAge可配置) ,从新到旧划分时间区间,其中时间越新,划分时间区间长度越短,然后对时间轴内区间的多个文件做合并,落在对应区间的KeyValue被写入到对应区间的storeFile内,最终合并的结果是每个区间只有一个文件,这个文件只包含自己区间内的数据。这种策略的好处在于数据越新,compaction越频繁,数据越旧,compaction越少(甚至不compaction),这种策略非常适合OpenTSDB,因为OpenTSDB写入数据都是按照时间递增,而之前的老数据从不修改,因此推荐OpenTSDB下的HBase集群采用DateTieredCompaction策略。
另外,PPT中还提到很多其他的内容,例如AsyncHBase的进展,OpenTSDB3.0的规划,OpenTSDB2.4的其他新特性等等,这里不再展开细评, 感兴趣可以读读PPT。
参考资料:
12. A study of Salesforce’s use of HBase and Phoenix ( by Salesforce )
主要介绍了Salesforce公司内部的HBase/Phoenix业务情况。
13. Cursors in Apache Phoenix (by bloomberg)
Bloomberg是一家研发NewSQL的数据库厂商,其核心产品是comdb2,目前已经在Github开源,其项目的介绍专门在VLDB2016上发了paper,感兴趣的同学可以读读。本次talk主要介绍他们是如何在phoenix上实现的关系型数据库中cursor功能。
14. Warp 10 - A novel approach for time series management and analysis based on HBase (by Herberts)
这个PPT主要应该是介绍他们的Wrap10项目。
15. Removable Singularity: A Story of HBaseUpgrade at Pinterest(by Pinterest)
Pinterest之前有40多个0.94版本的集群,他们面临着和小米一样的问题,就是需要把0.94版本的集群升级到1.2版本,而0.94版本HBase的rpc协议和1.2不兼容,前者是基于Writable接口的自定义协议,后者是Protobuf协议。解决问题的思路大致是一样的,就是先把快照数据通过ExportSnapshot导入1.2版本的HBase集群,再把增量数据通过thrift replication导入到新集群。后面需要考虑的问题就是业务如何实现在线切换。Pinterest比较有优势的一个地方就是,他们的业务使用的客户端是AsyncHBase1.7,而AsyncHBase1.7本身是支持0.94和1.2的,因此业务只需要修改访问HBase的集群地址就好。升级到1.2版本之后,无论是读性能还是写性能都有较好的提升。
16. Improving HBase availability in a multi-tenant environment (by Hubspot)
HBase在CAP中属于CP型的系统,可用性方面有一些缺陷,例如一个RegionServer宕机,Failover时长主要分3段,首先是故障检测的时间(<10s),然后是SplitLog的时间(20~40s),然后是最终RegionOnline的时间(10s~30s),数据取自Hubspot PPT。总体来讲,Failover时长优化空间较大。为此,Hubspot分享了一些提高HBase可用性的相关work:
- 测试发现将大集群拆分成更多小实例能减少总体的failover时间。
- 通过Normalizer控制Region的大小,使之均匀。
- HBASE-17707和HBASE-18164优化StochasticLoadBalancer策略,使balance更合理,更高效。
- 对每个用户消耗的RPC Handler做上限限制,社区版本貌似没这功能,应该是内部实现的。
- 使用内部硬件检测工具提前发现硬件问题,并移走HBase服务。
17. Highly Available HBase (by Sift Science)
Sift Science是一家通过实时机器学习技术来防止商业诈骗的公司, Uber/Airbnb等都是他们的客户。由于他们的业务跟钱相关,对HBase可用性要求非常高。经过一些优化之后, 他们成功将HBase的宕机时间从5小时/月优化到4分钟/月。这些优化工作主要有:
- 修改hbase-client代码,当client发现突然有较多请求失败时,client直接上抛DoNotRetryRegionException到上层,避免RS已经不可用时仍然被客户端大量请求导致大量handler被卡住,影响MTTR时间。
- 搭建在线备份集群,同时修改client代码,发现主集群有问题, client可以直接借助zk自动切换到备份集群。 存在的问题是,备份集群数据可能落后主集群,切换可能数据不一致。PPT上只是说会通过离线任务去抽样校验,所以,我觉得对于两集群的一致性问题,要么牺牲一致性保可用性,要么牺牲可用性保一致性。
- 加强监控,尤其是locality/balance状况/p99延迟这些,尽早发现问题并解决,而不是等出问题再解决。
18. Transactions in HBase (by cask.co)
这个talk应该是全场21个talk中干货最多的PPT之一,讨论的重点是基于HBase之上如何实现分布式事务。作者深入探讨了3种分布式事务模型,分别是Tephra/Trafodion/Omid,3个项目都是Apache下的孵化项目。这里,简单说一下我对这3种事务模型的理解:
- Tephra: 该模型本质上是通过一个叫做Trx Manager的集中式服务用来维护当前活跃事务,该TrxManager用来分配事务start/commit/rollback逻辑时钟,每个事务开始时都会分配一个ts和一个叫做excludes={…}的集合,用来维护该事务开始前的活跃事务,这个excludes集合可用来做隔离性检查,也可用来做冲突检查。由于有一个较为重量级的集中式TrxManager,所以事务高并发场景下该模型压力会较大,因此该模型推荐的用来运行并发少的long-running MapReduce之类的事务Job。
- Trafodion: 这个没太看懂和tephra的区别是啥。。ppt上看不太出来。
- Omid: Apache Omid事务模型和Google Percolator事务模型是类似的,小米研发的Themis也是一样,本质上是借助HBase的行级别事务来实现跨行跨表事务。每个事务begin和commit/rollback都需要去TimeOracle拿到一个全局唯一递增的逻辑timestamp,然后为每一个column新增两个隐藏的column分别叫做lock和write,用来跟踪每次写入操作的锁以及逻辑timestamp,通过2PC实现跨行事务提交。对于读取的4个隔离级别(RS, RR, SI, RU),有了全局唯一递增的逻辑时钟之后,也就很容易决定哪些数据应该返回给用户。
参考资料
1. http://andremouche.github.io/transaction/percolator.html
2. https://research.google.com/pubs/pub36726.html
3. https://github.com/xiaomi/themis
4. http://nosqlmark.informatik.uni-hamburg.de/sdb2014/res/paper/Omid.pdf
19. Achieving HBase Multi-Tenancy: RegionServer Groups and Favored Nodes
这个talk介绍了Yahoos主导的两个重要feature:RegionServer Group和Favored Nodes。
1. RegionServer Group可以让指定表分布在某些RegionServer上,一定程度上实现了多租户之间的隔离,相比Hortonworks在微观层面对多租户所做出的努力(rpc队列分离、quota机制、请求优先级等),个人认为rsGroup在多租户管理方面效果可能更加明显。rsGroup是这次峰会比较明星的话题,包括滴滴等公司都作为主旨来介绍其在生产实践中的应用,可见已经被很多大厂所接受并实践,遗憾的是,该功能目前只在未发布的2.0.0里面包含,要想在当前版本中使用必须移植对应patch,因为功能的复杂性,这看起来并不是一件容易的事情。
2. Favored Nodes机制相对比较陌生,该功能允许HBase在region层面指定该region上所有文件分布在哪些DN之上,这个功能最大的好处是可以提升数据文件的本地率,试想,每个Region都知道文件存放的DN,迁移Region的时候就可以多考虑文件本地率进行迁移。
20. Community-Driven Graphs With JanusGraph
这个talk介绍了HBase应用的另一个重要领域-图数据库,图数据库在互联网业务中诸多方面(社交图谱分析、推荐分析)都有实际应用。比如大家可能比较熟悉的titan数据库就是一个典型的图数据库。而这个主题介绍的是另一个图数据库 - JanusGraph,PPT中分别对JanusGraph的架构、存储模型以及如何使用HBase作为后端存储进行了详细的分析。对Graph比较感兴趣的童鞋可以重点关注!
最后,附上PPT下载链接: HBaseConWest2017
作者:胡争、范欣欣