Notes on HBaseCon West 2017 presentations:
1. HBase at Xiaomi
Presented jointly by Zhe Yang and Guanghao Zhang—both became HBase Committers in 2016 (Xiaomi has produced eight HBase Committers in total, including two PMC members, and has resolved hundreds of issues). Highlights included:
- Lessons from upgrading clusters from 0.94 to 0.98.
- Experience using G1GC for internal HBase deployments.
- Community contributions and improvements in 2016, including ordered replication log push, Scan optimizations, async client development, and related benchmark results.
2. Apache HBase at DiDi (by Kang Yuan)
Practical experience running HBase at DiDi. Their deployment is based on 0.98.21 with the rsgroup feature ported to a private branch for workload isolation. The talk also described encoding geographic coordinates as one-dimensional bytes via GeoHash in HBase to support nearby-point queries.
3. Accordion: HBase Breathes with In-Memory Compaction (From Yahoo)
With in-memory compaction, HBase can flush a memstore directly into an ImmutableSegment—a block of memory. Multiple flushes create multiple ImmutableSegments; under certain conditions they are compacted entirely in memory into one larger ImmutableSegment. BASIC in-memory compaction retains all data; EAGER compaction removes redundant versions. The large ImmutableSegment is eventually flushed to disk and triggers on-disk compaction.
According to the design doc and slides, in-memory compaction helps because:
- Compaction happens in memory, reducing frequent memstore flushes to disk (too many flushes grow store file count and hurt read latency), which lowers read latency.
- ImmutableSegment layout may align with HFile layout, speeding up flush.
- For workloads with frequent row updates, EAGER compaction can drop redundant versions in memory before they hit disk.
Benchmarks in the slides showed higher write throughput and lower read latency with in-memory compaction.
In-memory compaction was built by Stack and five others (shipping in HBase 2.0). Two of the engineers on the team (shown in the slides) are now HBase Committers. Design details: https://issues.apache.org/jira/browse/HBASE-13408
4. Efficient and portable data processing with Apache Beam and HBase (By Google)
This talk mainly promoted Apache Beam. Started in February 2016, the project received 8,600+ commits from 178 contributors worldwide. It offers a unified API for batch and streaming, with backends such as Apex, Flink, Spark, and Google Cloud Dataflow, plus Java and Python SDKs—similar in spirit to JDBC unifying access to MySQL, Oracle, PostgreSQL, SQL Server, and so on. If I understood correctly, Beam can transform data across HBase, MongoDB, HDFS, Cassandra, Kafka, Bigtable, Spanner, Elasticsearch, GridFS, Hive, AMQP, and more than 20 other storage systems.
5. Data Product at Airbnb
Airbnb’s use cases for HBase and how they run batch and streaming workloads on a unified stack.
6. Democratizing HBase (by Hortonworks)
Josh Elser (Hortonworks, HBase Committer) works on several Apache projects including HBase and Phoenix. The talk covered multi-tenant resource isolation: security, RPC quotas, RPC priorities, space quotas, RegionServer groups, and related work.
7. Apache Spark – Apache HBase Connector Feature Rich and Efficient Access to HBase through Spark SQL (by Hortonworks)
Overview of Hortonworks’ open-source SHC project.
8. Gohbase: Pure Go HBase Client (by Arista Networks)
Non-Java clients (Python, Go, JavaScript) often use Thrift-generated SDKs that talk to HBase’s Thrift server; the Thrift server then uses the Java native client to reach RegionServers and Master. Thrift-generated APIs tend to be low-level, and early ThriftServer had many bugs.
The speaker implemented a pure Go HBase client on HBase’s Protobuf protocol—essentially reimplementing the Java native client in Go. It should be more pleasant to use than other Go SDKs and, in some scenarios, faster than the Java client.
While building Gohbase, the author found HBASE-18066, since fixed by Xiaomi’s openinx. For Get with closestRowBefore=true, the RegionServer first resolved the row key without MVCC, then fetched the value with MVCC—so the result could be inconsistent. The fix routes these operations through reversed scan, which uses MVCC consistently.
9. Analyzing Cryptocurrencies on HBase For Finance, Forensics, and Fraud (by Ripple)
Ripple is a cryptocurrency somewhat like Bitcoin, backed by a commercial company. The talk focused on Ripple’s business and HBase use cases.
10. Splice Machine: Powering Hybrid Applications (by Splice Machine)
Splice Machine offers database-as-a-service on Hadoop. The demo walked through their cloud products; worth a look if you care about HBase in the cloud.
11. OpenTSDB: 2.4 and 3.0 update (by Yahoo)
The speaker has maintained OpenTSDB for nearly four years—dense content. OpenTSDB is a time-series database on HBase with horizontal scale-out. Row key design in HBase:
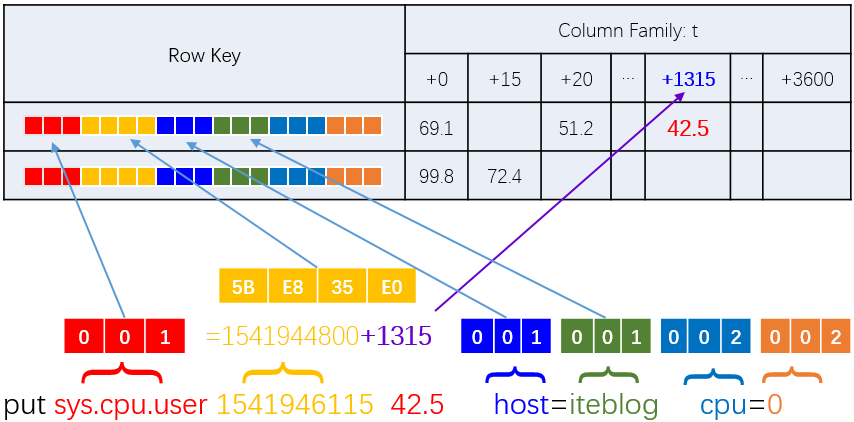
This row key supports queries by metric + timestamp + tag combinations—roughly:
select * from table where metric=? and ts < ? and ts > ? and (tag_i= ?) and (tag_j= ?)
For a wide time range (e.g. 24 hours of metrics), data spans 24 rows, so you need 24 seek+read operations. Long-range queries must sample at lower resolution for acceptable performance.
HBASE-15181 added DateTieredCompaction. It partitions the time axis (typically [now - maxAge, now], with configurable maxAge) from newest to oldest—shorter intervals for newer data—and compacts files per interval so each interval ends with one store file containing only that interval’s data. Newer data is compacted more often; older data less or not at all. That fits OpenTSDB well: writes are time-ordered and old data is immutable, so OpenTSDB clusters benefit from DateTieredCompaction.
The slides also covered AsyncHBase progress, OpenTSDB 3.0 plans, OpenTSDB 2.4 features, and more—see the deck for details.
References:
12. A study of Salesforce’s use of HBase and Phoenix (by Salesforce)
HBase and Phoenix usage inside Salesforce.
13. Cursors in Apache Phoenix (by Bloomberg)
Bloomberg builds NewSQL databases; their core product comdb2 is open source on GitHub with a VLDB 2016 paper. This talk described implementing relational cursors on Phoenix.
14. Warp 10 - A novel approach for time series management and analysis based on HBase (by Herberts)
Overview of the Warp 10 project.
15. Removable Singularity: A Story of HBase Upgrade at Pinterest (by Pinterest)
Pinterest had 40+ clusters on 0.94 and faced the same upgrade challenge as Xiaomi: move to 1.2 where RPC protocols differ—Writable-based custom protocol vs. Protobuf. The approach matches Xiaomi’s: export snapshots into 1.2 clusters, then replicate incremental data via Thrift replication. Online cutover is the hard part. Pinterest had an advantage: clients use AsyncHBase 1.7, which supports both 0.94 and 1.2, so switching cluster endpoints was enough. After upgrade, read and write performance improved noticeably.
16. Improving HBase availability in a multi-tenant environment (by Hubspot)
HBase is CP in the CAP sense; availability has gaps. When a RegionServer fails, failover breaks into roughly: failure detection (<10s), split log (20–40s), and region online (10–30s)—figures from Hubspot’s slides. Failover time has room to improve. Hubspot shared work to raise availability:
- Splitting large clusters into smaller instances reduced total failover time in tests.
- Normalizer to keep region sizes even.
- HBASE-17707 and HBASE-18164 to improve StochasticLoadBalancer.
- Per-user caps on RPC handler usage (likely internal; not in community builds).
- Internal hardware checks to catch failures early and drain HBase from bad nodes.
17. Highly Available HBase (by Sift Science)
Sift Science uses real-time ML to fight fraud; customers include Uber and Airbnb. With money on the line, they need high HBase availability. After optimization, monthly downtime dropped from five hours to four minutes. Key changes:
- Client changes: when many requests fail at once, propagate
DoNotRetryRegionExceptionupward so clients do not hammer a dead RegionServer and tie up handlers, hurting MTTR. - Online backup cluster plus client logic to fail over via ZooKeeper when the primary is unhealthy. Backup data may lag; cutover can be inconsistent. They rely on offline sampling checks—so you either sacrifice consistency for availability or the reverse.
- Stronger monitoring on locality, balance, and p99 latency to catch issues early.
18. Transactions in HBase (by cask.co)
One of the most substantive talks among 21—distributed transactions on HBase. The author compared three models: Tephra, Trafodion, and Omid (all Apache incubating projects). Brief notes:
- Tephra: A centralized Trx Manager assigns start/commit/rollback logical clocks. Each transaction gets a timestamp and an
excludes={...}set of active transactions at start time—for isolation and conflict checks. The centralized manager is heavy under high concurrency; suited to low-concurrency long-running MapReduce-style jobs. - Trafodion: Hard to distinguish from Tephra from the slides alone.
- Omid: Similar to Google Percolator (Xiaomi’s Themis follows the same idea)—row-level HBase transactions extended to cross-row/cross-table via hidden lock/write columns, global timestamps from a TimeOracle, and 2PC. With a global logical clock, read isolation levels (RS, RR, SI, RU) are straightforward.
References
- http://andremouche.github.io/transaction/percolator.html
- https://research.google.com/pubs/pub36726.html
- https://github.com/xiaomi/themis
- http://nosqlmark.informatik.uni-hamburg.de/sdb2014/res/paper/Omid.pdf
19. Achieving HBase Multi-Tenancy: RegionServer Groups and Favored Nodes
Yahoo-led features: RegionServer Group and Favored Nodes.
- RegionServer Group pins tables to subsets of RegionServers for multi-tenant isolation. Compared with Hortonworks’ finer-grained work (RPC queue separation, quotas, priorities), rsGroup may be more visible at the cluster level. It was a hot topic at the conference—DiDi and others presented production use. Unfortunately it ships only in unreleased 2.0.0; backporting the patch is non-trivial.
- Favored Nodes lets HBase specify which DataNodes should host a region’s files, improving locality. When moving regions, the balancer can favor nodes that already hold the data.
20. Community-Driven Graphs With JanusGraph
Graph databases on HBase—social graphs, recommendations, and more. Titan is a well-known example; this session covered JanusGraph architecture, storage model, and using HBase as the backend. Worth attention if you care about graphs.
Slides: HBaseConWest2017
Authors: Zheng Hu, Fan Xinxin