初衷
对数据库来说,满足业务多样化的查询方式非常重要。如果说有人设计了一个KV数据库,只提供了Get/Put/Scan这三种接口,估计要被用户吐槽到死,毕竟现实的业务场景并不简单。就以订单系统来说,查询给定用户最近三个月的历史订单,这里面的过滤条件就至少有2个:1. 查指定用户的订单;2. 订单必须是最近是三个月的。此外,这里的过滤条件还必须是用AND来连接的。如果通过Scan先把整个订单表信息加载到客户端,再按照条件过滤,这会给数据库系统造成极大压力。因此,在服务端实现一个数据过滤器是必须的。
除了上例查询需求,类似小明或小黄最近三个月的历史订单这样的查询需求,同样很常见。这两个查询需求,本质上前者是一个AND连接的多条件查询,后者是一个OR连接的多条件查询,现实场景中AND和OR混合连接的多条件查询需求也很多。因此,HBase设计了Filter以及用AND或OR来连接Filter的FilterList。
例如下面的过滤器,表示用户将读到rowkey以abc为前缀且值为testA的那些cell。
fl = new FilterList(MUST_PASS_ALL,
new PrefixFilter("abc"),
new ValueFilter(EQUAL, new BinaryComparator(Bytes.toBytes("testA")))
);
实际上,FilterList内部的子Filter也可以是一个FilterList。例如下面过滤器表示用户将读到那些rowkey以abc为前缀且值为testA或testB的f列cell列表。
fl = new FilterList(MUST_PASS_ALL,
new PrefixFilter("abc"),
new FamilyFilter(EQUAL, new BinaryComparator(Bytes.toBytes("f"))),
new FilterList(MUST_PASS_ONE,
new ValueFilter(EQUAL, new BinaryComparator(Bytes.toBytes("testA"))),
new ValueFilter(EQUAL, new BinaryComparator(Bytes.toBytes("testB")))
)
);
因此,FilterList的结构其实是一颗多叉树。每一个叶子节点都是一个具体的Filter,例如PrefixFilter、ValueFilter等;所有的非叶子节点都是一个FilterList,各个子树对应各自的子filter逻辑。对应的图示如下:
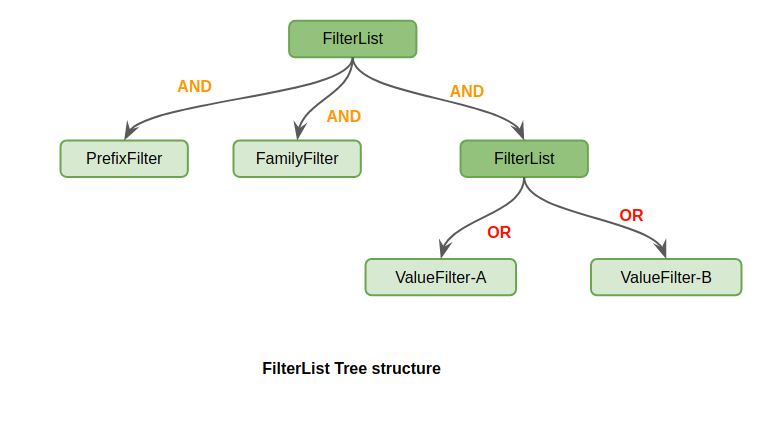
当然,HBase还提供了NOT语义的SkipFilter,例如用户想拿到那些rowkey以abc为前缀但value既不等于testA又不等于testB的f列的cell列表,可用如下FilterList来表示:
fl = new FilterList(MUST_PASS_ALL,
new PrefixFilter("abc"),
new FamilyFilter(EQUAL, new BinaryComparator("f")),
new SkipFilter(
new FilterList(MUST_PASS_ONE,
new ValueFilter(EQUAL, new BinaryComparator(Bytes.toBytes("testA"))),
new ValueFilter(EQUAL, new BinaryComparator(Bytes.toBytes("testB")))
)
));
实现
Filter和FilterList作为一个通用的数据过滤框架,提供了一系列的接口,供用户来实现自定义的Filter。当然,HBase本身也提供了一系列的内置Filter,例如:PrefixFilter、RowFilter、FamilyFilter、QualifierFilter、ValueFilter、ColumnPrefixFilter等。
事实上,很多Filter都没有必要在服务端从Scan的startRow一直扫描到endRow,中间有很多数据是可以根据Filter具体的语义直接跳过,通过减少磁盘IO和比较次数来实现更高的性能的。以PrefixFilter(“333”)为例,需要返回的是rowkey以“333”为前缀的数据。
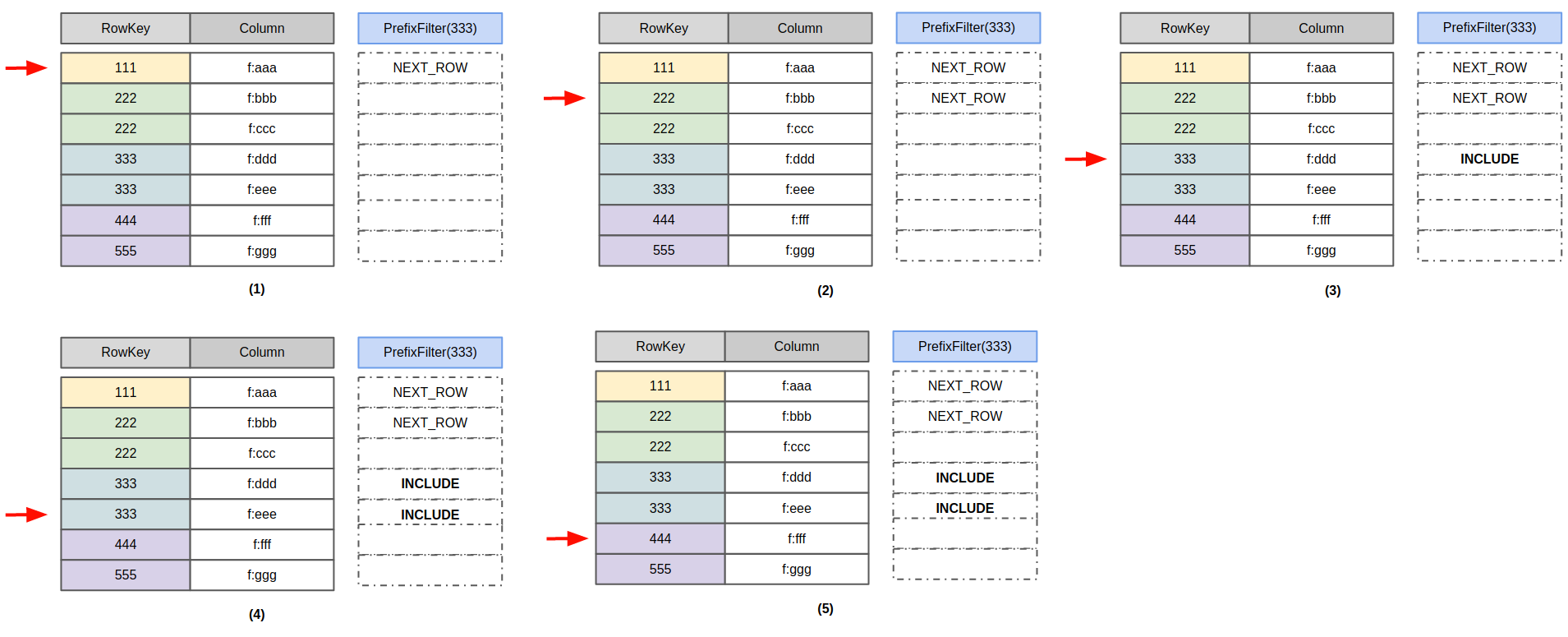
实际的扫描流程如图所示:
- 碰到rowkey=111的行时,发现111比前缀333小,因此直接跳过111这一行去扫下一行,返回状态码NEXT_ROW;
- 下一个Cell的rowkey=222,仍然比前缀333小,因此继续扫下一行,返回状态NEXT_ROW;
- 下一个Cell的rowkey=333,前缀和333匹配,返回column=f:ddd这个cell个用户,返回状态码为INCLUDE;
- 下一个Cell的rowkey仍为333,前缀和333匹配,返回column=f:eee这个cell给用户,返回状态码为INCLUDE;
- 下一个Cell的rowkey为444,前缀比333大,不再继续扫描数据。
这个流程中,每碰到一个Cell,返回的状态码NEXT_ROW、INCLUDE等,就告诉了RegionServer扫描框架下一个Cell的位置。例如在第2步中,返回状态码NEXT_ROW,那么下一个Cell的rowkey必须是比222大的,于是就跳过了column=f:ccc这个Cell,直接定位到了rowkey=333的行,继续扫描数据。
在实际的Filter设计中,共引入了INCLUDE、INCLUDE_AND_NEXT_COL、SKIP、NEXT_COL、NEXT_ROW、SEEK_NEXT_USING_HINT共6种状态码。其中INCLUDE表示当前Cell应该返回给用户,同时自动读下一个Cell;INCLUDE_AND_NEXT_COL类似,表示当前Cell返回给用户,同时需要切换到下一个Column的Cell,也就是跟当前Cell相同Column的Cell都被跳过。SEEK_NEXT_USING_HINT表示下一个待读取的Cell是用户根据Filter语义自定义的一个Cell,例如对PrefixFilter(333)来说,碰到rowkey=111的行时,其实是可以根据前缀为333直接定位到下一个rowkey=333的Cell,只是当前的PrefixFilter没有做这个优化。
FilterList在处理状态码时则要稍微复杂一点,因为对同一个Cell每个子Filter的状态码都可能不一样,因此需要对多个子Filter的状态码进行合并。例如:
fl = new FilterList(MUST_PASS_ALL,
new PrefixFilter("abc"),
new ValueFilter(EQUAL, new BinaryComparator(Bytes.toBytes("testA")))
);
在碰到rowkey=abb且value=testA的Cell(记为Cell-A)时,PrefixFilter返回的状态码应该是NEXT_ROW,而ValueFilter返回的状态码应该是INCLUDE。对于用AND来连接的FilterList来说,应该取各状态码中跳跃步数最大的状态码,因此对Cell-A来说,fl这个FilterList得到的状态码将会是:max(NEXT_ROW, INCLUDE) = NEXT_ROW。
简单来说,对某个Cell,用AND连接的FilterList,必须选各子Filter状态码跳跃步数最大的那个状态码;而用OR连接的FilterList,必须选各子Filter状态码跳跃步数最小的那个状态码。这其实是FilterList对比正常Filter来说,需要实现的一个最核心的工作,我们很早之前就在HBASE-18410将这块代码进行模块化重构,HBase1.4.x之后的版本都是使用重构之后的代码,用户在使用新版本FilterList时可以获得更精准的语义保证了。
一些优化
1.通过设置StartRow和StopRow替换PrefixFilter
PrefixFilter是将rowkey前缀为指定字节串的数据都过滤出来并返回给用户。例如,如下scan会返回所有rowkey前缀为’def’的数据。
Scan scan = new Scan();
scan.setFilter(new PrefixFilter(Bytes.toBytes("def")));
注意,这个scan虽然能拿到预期的效果,但却并不高效。因为对于rowkey在区间(-oo, def)的数据,scan会一条条依次扫描一次,发现前缀不为def,就读下一行,直到找到第一个rowkey前缀为def的行为止。
这主要是因为目前HBase的PrefixFilter设计的相对简单粗暴,没有根据具体的Filter做过多的查询优化。这种问题其实很好解决,在scan中简单加一个startRow即可,RegionServer在发现scan设了StartRow,首先寻址定位到这个StartRow,然后从这个位置开始扫描数据,这样就跳过了大量的(-oo, def)的数据。代码如下:
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes("def"));
scan.setFilter(new PrefixFilter(Bytes.toBytes("def")));
当然,更简单直接的方式,就是将PrefixFilter直接展开成扫描[def, deg)这个区间的数据,这样效率是最高的,代码如下:
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes("def"));
scan.setStopRow(Bytes.toBytes("deg"));
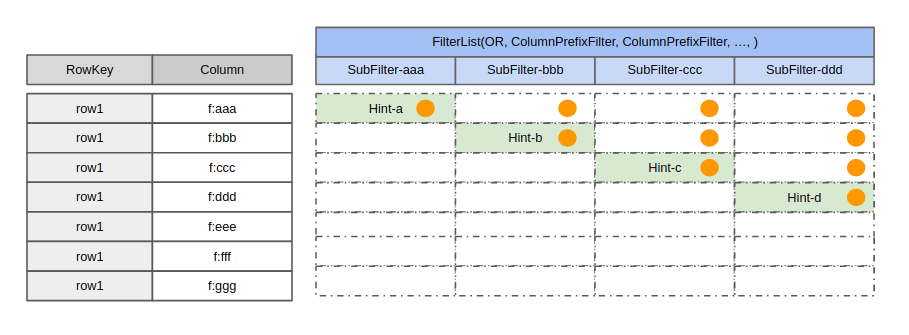
2.用MultipleColumnPrefixFilter来替换掉FilterList(OR, ColumnPrefixFilter, ColumnPrefixFilter, …)
在HBASE-22448,有用户提到,写一个如下的FilterList会显的特别慢:
fl = new FilterList(MUST_PASS_ONE,
new ColumnPrefixFilter(Bytes.toBytes("aaa")),
new ColumnPrefixFilter(Bytes.toBytes("bbb")),
...
new ColumnPrefixFilter(Bytes.toBytes("zzz"))
)
这是因为采用FilterList(OR, ColumnPrefixFilter,…)的比较次数如下图所示,每个橙色的实心圆圈表示一次Cell的Compare操作。
经过讨论和测试后,发现其实是可以用MultipleColumnPrefixFilter来替换上述FilterList(OR,ColumnPrefixFilter,…)的。代码如下:
fl = new MultipleColumnPrefixFilter(byte[][] {
Bytes.toBytes("aaa"),
Bytes.toBytes("bbb"),
...,
Bytes.toBytes("zzz")
});
通过评估,我们发现Cell的比较次数如下图所示:
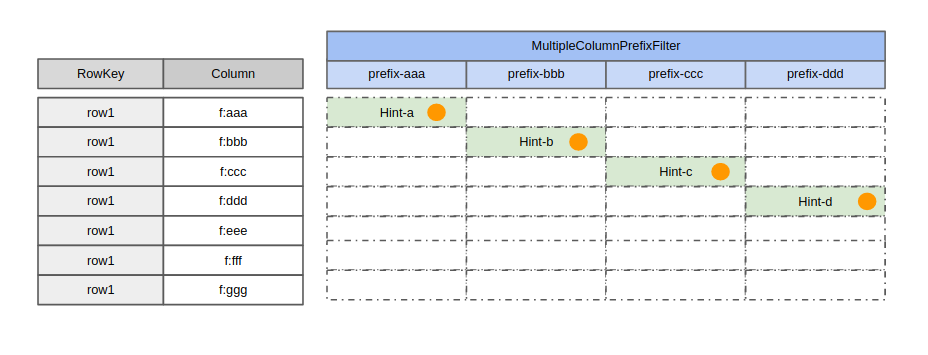
二者对比发现,采用MultipleColumnPrefixFilter之后可以减少大量的比较次数。事实上,用HBASE-22448上的测试数据对比,发现优化后的性能快20倍:
这个案例带给我们的启发是,如果发现某些场景下采用通用的FilterList框架无法满足业务的性能需求,那么实际上可以尝试采用自定义Filter的方式来满足更高的性能需求。因为在自定义的Filter中,我们可以通过更少的比较次数来实现优化,而FilterList框架为了保证通用逻辑的正确性则无法实现。
3.关于SingleColumnValueFilter的语义
这个Filter的定义比较复杂,让人有点难以理解。举例来说:
Scan scan = new Scan();
SingleColumnValueFilter scvf = new SingleColumnValueFilter(
Bytes.toBytes("family"),
Bytes.toBytes("qualifier"),
CompareOp.EQUAL,
Bytes.toBytes("value")
);
scan.setFilter(scvf);
这个例子表面上是将列簇为family、列为qualifier且值为value的cell返回给用户。但事实上,对那些不包含family:qualifier这一列的行,也会被默认返回给用户。如果用户不希望读取那些不包含family:qualifier的数据,需要设计如下scan:
Scan scan = new Scan();
SingleColumnValueFilter scvf = new SingleColumnValueFilter(
Bytes.toBytes("family"),
Bytes.toBytes("qualifier"),
CompareOp.EQUAL,
Bytes.toBytes("value")
);
scvf.setFilterIfMissing(true); // 跳过不包含对应列的数据
scan.setFilter(scvf);
另外,当SingleColumnValueFilter设置filterIfMissing为true时,和其他Filter组合成FilterList时,可能导致返回结果不正确(参见HBASE-20151)。因为filterIfMissing设为true时,SingleColumnValueFilter必须要遍历一行数据中的每一个cell, 才能确定是否过滤,但在filterList中,如果其他的Filter返回NEXT_ROW会直接跳过某个列簇的数据,导致SingleColumnValueFilter无法遍历一行所有的cell,从而导致返回结果不符合预期。 对于这个问题,个人建议是:不要使用SingleColumnValueFilter和其他Filter组合成FilterList。尽量通过ValueFilter来替换掉SingleColumnValueFilter。
4.关于PageFilter
在HBASE-21332中,有一位用户说,有一个表,表里面有5个Region,分别为(-oo, 111), [111, 222), [222, 333), [333, 444), [444, +oo)。 表中这5个Region,每个Region都有超过10000行的数据。他发现通过如下scan扫描出来的数据居然超过了3000行:
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes("111"));
scan.withStopRow(Bytes.toBytes("4444"));
scan.setFilter(new PageFilter(3000));
乍一看确实很诡异,因为PageFilter就是用来做数据分页功能的,应该要保证每一次扫描最多返回不超过3000行。但是需要注意的是,HBase里面Filter状态全部都是Region内有效的,也就是说,Scan一旦从一个Region切换到另一个Region之后, 之前那个Filter的内部状态就无效了,新Region内用的其实是一个全新的Filter。具体这个问题来说,就是PageFilter内部计数器从一个Region切换到另一个Region之后,计数器已经被清0。 因此,这个Scan扫描出来的数据将会是:
在[111,222)区间内扫描3000行数据,切换到下一个region [222, 333)。
在[222,333)区间内扫描3000行数据,切换到下一个region [333, 444)。
在[333,444)区间内扫描3000行数据,发现已经到达stopRow,终止。
因此,最终将返回9000行数据。理论上说,这应该算是HBase的一个缺陷,PageFilter并没有实现全局的分页功能,因为Filter没有全局的状态。我个人认为,HBase也是考虑到了全局Filter的复杂性,所以暂时没有提供这样的实现。 当然如果想实现分页功能,可以不通过Filter,而直接通过limit来实现,代码如下:
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes("111"));
scan.withStopRow(Bytes.toBytes("4444"));
scan.setLimit(1000);
所以,正常情况下对用户来说,PageFilter并没有太多存在的价值。
总结
这些年社区的Filter和FilterList模块基本上是由小米HBase团队来负责维护和改进的。总结起来,一方面,本身HBase读路径上的概念繁多,诸如版本号、DeleteMarker、TTL、行、Family、列等,为实现这些功能读路径已经较为复杂;另一方面,Filter本身是一个高度抽象的框架,用户可以基于这个抽象的框架实现各种各样自定义的过滤器,实现需要考虑各种现实场景的适用性。对普通用户来说,正确和高效的使用,有一定的小门槛,因此写了这篇文章,希望对用户正确的使用和理解Filter以及FilterList有所帮助。