最近参加了TiDB的Hackthon2019比赛,一直都想写一篇总结,现在总算有点时间来写一下。
这是一个围绕 TiDB 分布式数据库展开的一个编程比赛,在 48 小时内完成一个可以展示的 demo,并在 6 分钟内向评委说明项目思路及展示demo。理论上,要求这个demo从实用性、易用性、性能三个方面来优化TiDB(占评分40%),“当然作品的完成度也是一个很重要的考核方向(占30%),其他就是创新性(占20%)和展示度了(占10%)。
我们队共有三个同学:队长是来自 PingCAP 美国 office 的吴毅同学,他之前在 facebook 负责 RocksDB 的研发,目前在PingCAP 主要负责 RocksDB 的研发和性能优化,另外一个北京 office 的张博康同学,负责TiKV的研发。由于我们队三个人都是做存储底层的研发,所以就想尝试在今年的 Hackthon 上做一些偏底层的工作。在比赛前,我们大致确认可能会尝试的几个小方向:
第一个是做一套 TiKV 的分布式 trace,用来跟进一个 TiKV 请求整个生命周期的耗时情况,便于诊断性能。由于这是一个非常普遍的方向,我们预估可能会有不少团队跟我们撞车,另外印象中现在 TiKV 已经实现了部分工作,所以就没有选择这个方向。
第二个是把一个图查询引擎套在 TiKV 之上,实现一个图数据库。我们初步想好可以用这个图数据库展示社交网络中的三度人脉。在不需要我们开发前端的前提下,可以借助开源的图查询前端来展示 demo,至少演示上不会吃亏。这个其实是一个不错的候选,但不确定工作量有多大,最后也没有选择这个方向。
第三个是用最新 linux 引入的高性能纯异步实现的 IO 接口 liburing 来重写部分 rocksdb 的实现,期望能给 TiKV 带来更好的性能提升。这个课题看起来跟我们三个成员的背景比较匹配,于是最终我们选择了这个课题。

我们队吴毅和博康选择在北京 office 比赛,而我离上海比较近,所以就去了上海。为此还申请了异地组队权限(感谢下PingCAP 开放的组委会),我们应该是唯一的三人两地的队伍了。
我们大致阅读了 liburing 的技术文档,大致确定可以尝试用这套异步 IO 接口重写 RocksDB 的写 WAL 流程和Compaction 流程。另外也调研到 facebook 之前已经尝试过用 io_uring 重写 RocksDB 的 MultiRead 实现,发现随机读的 IOPS 能翻三倍,接口延迟也下降不少,所以我们想用 TiKV 的一个场景来说明可以从中获得性能收益。
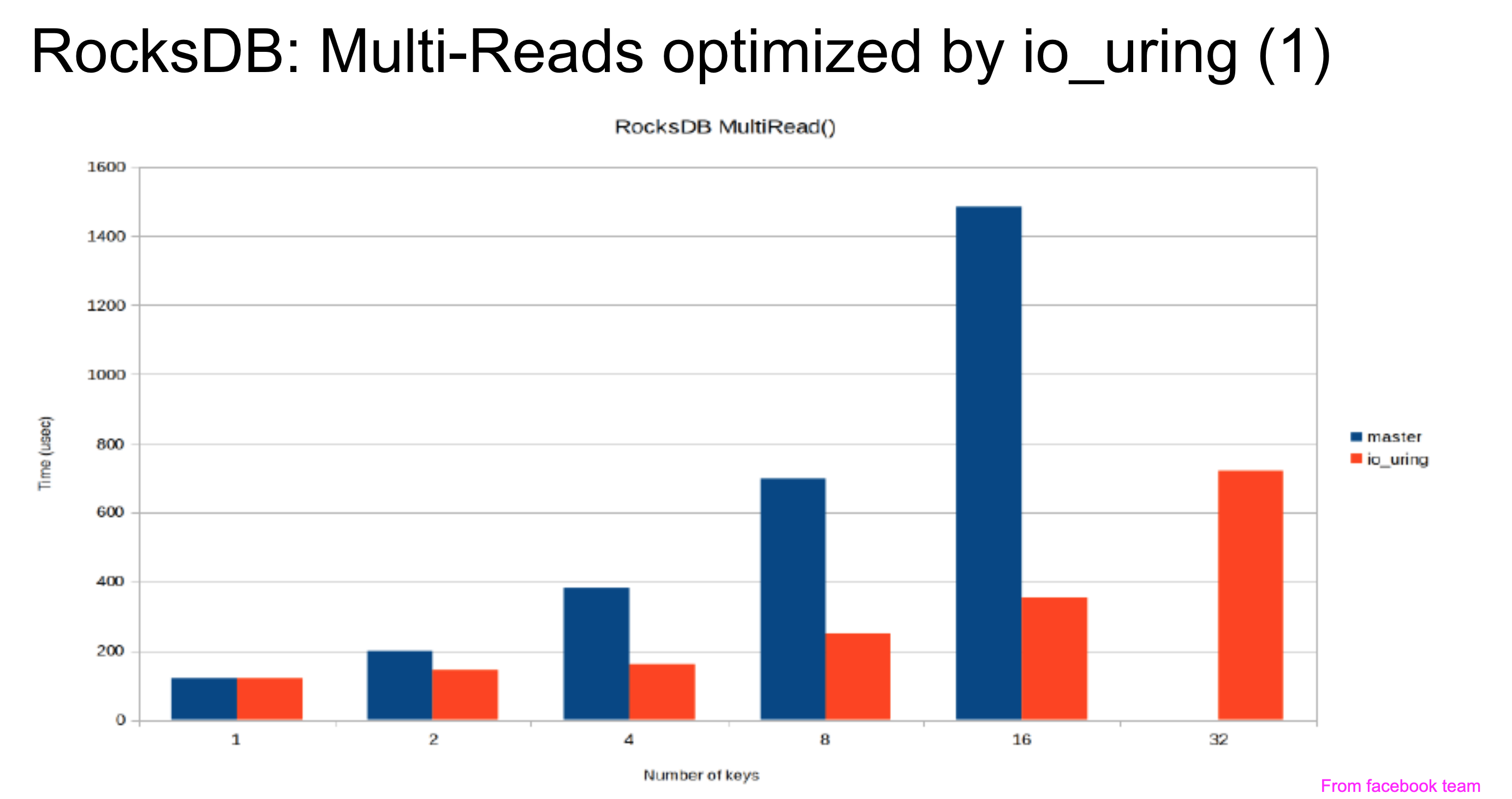
我们觉得有了这三个 Case 的性能数据,已经足够说明 io_uring 对 TiDB 的性能价值了。
比赛的第一天,我们基本完成了用 io_uring 重写 RocksDB 写 WAL 流程。但是跑了下 benchmark 发现,不用 io_uring 优化和用 io_uring 优化的RocksDB写入性能基本差不多。后面看了下,有个bug。修复之后,再测了一把发现io_uring优化后的性能远远好于没优化的状态。这是当时测试出来的数据,明显可以看出来优化后write+fsync的带宽比未优化快了一倍。
master: fillrandom : 77.439 micros/op 12913 ops/sec; 1.4 MB/s
uring : fillrandom : 36.503 micros/op 27394 ops/sec; 3.0 MB/s
看到这个数据,直觉告诉我们这肯定是不对的。因为毕竟io_uring主要优化批量io的吞吐,现在我们只改写了write+sync差距不应该有一倍之巨。于是,我们开始各种review代码,再反复读io_uring 17页的技术文档。最后,决定写个简单的小程序来确认io_uring接口和native的write+sync差距到底有多大,注意,这其实是定位问题最常用的思路,就是通过排除法缩小问题的范围,例如这里如果我们排除了io_uring接口本身造成的巨大差距,那么马上就可以定位是Linux接口上层的问题,而不是Linux接口本身的问题。测了一下,数据显示io_uring接口本身比Linux write+sync接口快10%左右。这就说明是我们上层写错了,导致之前测试结果的巨大差距。
花了一点时间查了下,发现是由于代码每次直接查了下队首的complete event而没有出队列,这就相当于write+sync的时候,sync其实就没有卡在那里等。于是uring优化write+sync的代码写成write+write的代码,这带宽当然比未优化要好太多。 改了这个bug之后,又发现压测RocksDB老是crash。
于是我们又开始翻RocksDB写入路径的各种代码以及Linux API的文档。结果还是没有找到root cause,“但后面又想了下这个结果肯定不行,最后决定再仔细缕一下每一行代码。最后我提了几段review comment之后,跟吴毅讨论某一段代码,吴毅突然想起改的Pull Request里那个io_uring_prep_write(seq, fd_, iov, 1, filesize_),其中iov是个局部变量,内存会随着函数跑完而释放,导致io_uring_prep_write这个异步方法访问到一个被释放掉的内存地址,于是最终coredump。
简单来说,就是这么一个场景:
void run(){
int[100] iov;
//...
io_uring_prep_write(seq, fd_, iov, 1, filesize_);
//...
//end of run function()
}
由于io_uring_prep_write是异步执行的,所以在run函数中iov退出之后,io_uring_prep_write内部实现其实还需要访问iov内存,但是由于iov是个局部变量,所以退出了run()函数内存就被释放。于是造成了coredump。
找到这个问题之后,修复了一下。最终测试出来的结果还是比较合理的。
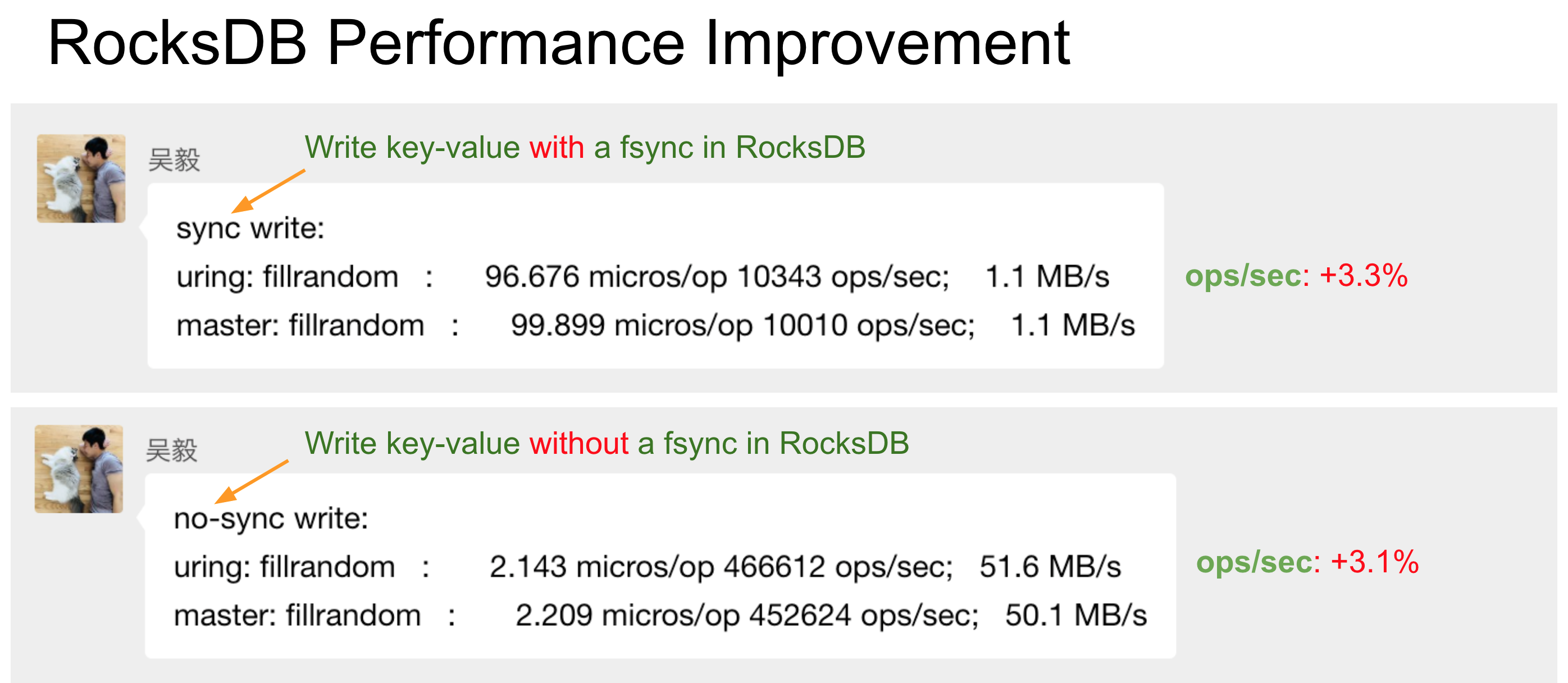
用uring优化之后能提升3%的ops,这里效果不是特别明显,但是足以说明io_uring的优化效果。至于不明显的原因,我们想了下可能有这么几点:
1.测试的数据量较小且测试路径没开O_DIRECT,所以数据都cache在page cache中了。也就是说这个3%的性能提升,基本上来自linux内核代码实现本身的优化,而不是批量磁盘设备IO带来的收益。这其实在大数据量下(或者走O_DIRECT写入)是能看出差异的。
2.批量IO太少,这里我们只有write+sync两个IO操作是异步的(如下图所示),所以其实多次write+sync还是同步的,效果肯定不会有太大的提升。
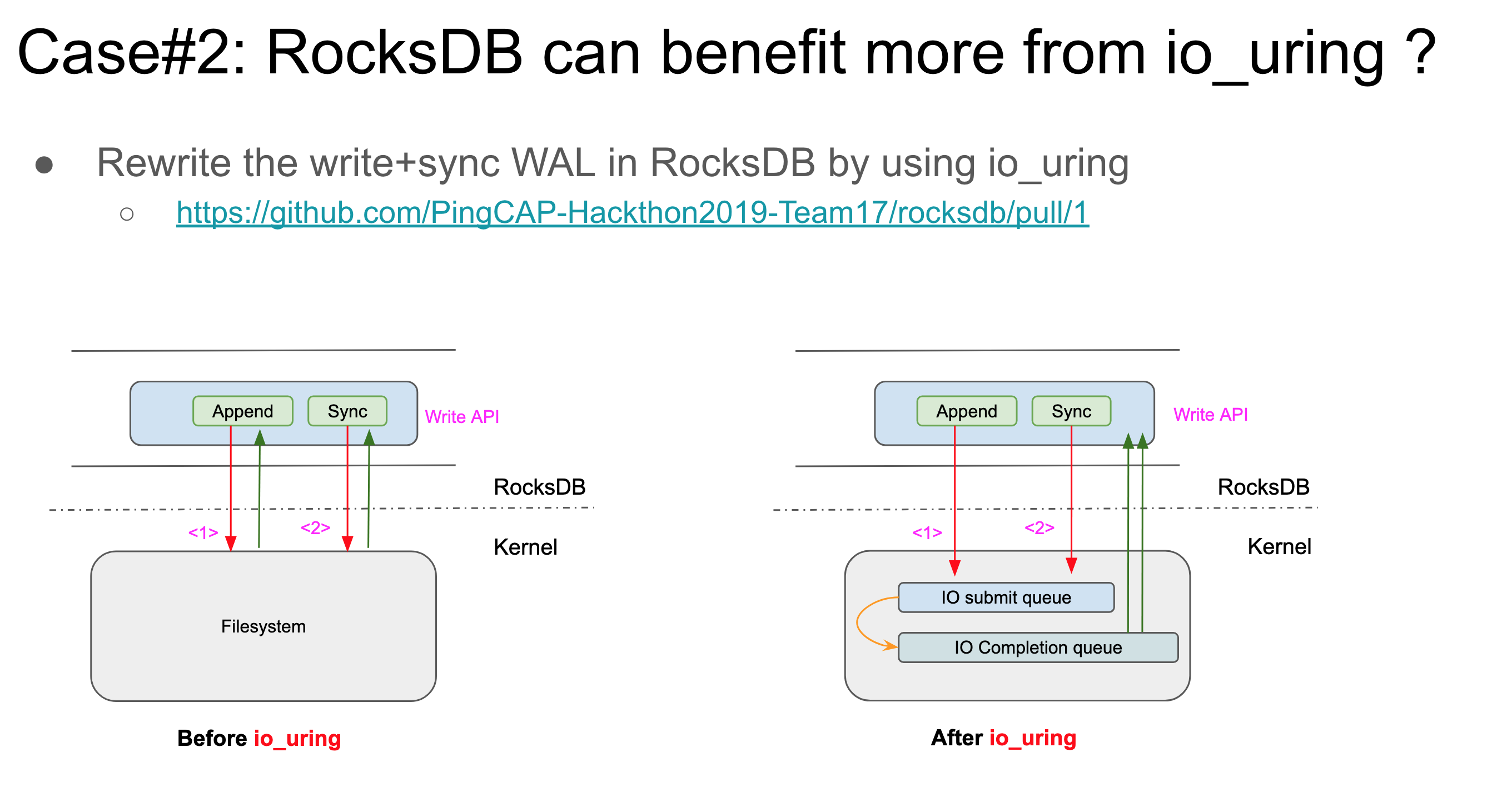
当然,后续我们还针对MultiRead和Compaction两种场景做了异步话,性能也有不同程度的提升,这里不再赘述。感兴趣的朋友可以参考我们最后答辩的PPT。
虽说这个项目最后并没有拿到什么奖,但是我们觉得这是一次很好的性能优化实践,未来TiKV也会把io_uring作为他们的技术储备,这也是我们乐于看到的。
再谈一下对这个比赛的看法。去年比赛总共有80+人参加,基本上20只队伍,感觉今年人气旺了很多,有120+人参加,共有40+只队伍,整个比赛评审一直持续到晚上9点多,我们这些参赛者都不得不在路上看直播评审(毕竟得回家赶高铁)。另外一个感受是,这种比赛对于上层的项目更加友好,而对于底层的项目相对不友好,记得有个组演示了下在浏览器里面跑TiDB,在浏览器里通过SQL终端连上服务端执行show databases那一刻,底下一群观众在不断鼓掌,我就觉得他们这个组肯定能拿个大奖。毕竟在整个技术栈中,从上层到下层,能理解的受众逐级递减,到了我们优化Linux API的这波人,底下基本没几个愿意听的。演示6分钟会相对吃亏,同时底层的性能优化短期内也难以收到很明显的成效,这些都是做底层项目的劣势吧,所以给组委会的一个建议就是需要更多的鼓励一下底层demo实现,否则未来的Hackthon会有更多的团队选择做上层甚至前端项目,而不愿意做底层的性能优化。
最后,我个人在这个比赛中可以全身心的投入写代码和解决问题,还是玩的挺开心的。感谢PingCAP提供的平台,让我认识了一群有趣的人。