I joined TiDB’s Hackathon 2019 and finally have time to write this recap.
A 48-hour hackathon around TiDB: build a demo, present in six minutes. Scoring weights practicality, ease of use, and performance for TiDB (40%), completeness (30%), innovation (20%), and presentation (10%).
Our team of three: captain Yi Wu from PingCAP’s US office (ex-Facebook RocksDB, now RocksDB at PingCAP), and Bokang Zhang in Beijing (TiKV). All three work on storage, so we aimed at the bottom of the stack. Before the event we shortlisted:
First: distributed tracing for TiKV request lifetimes—useful for perf diagnosis. Likely to collide with other teams; TiKV already had partial tracing—skipped.
Second: a graph query engine on TiKV (e.g. three-hop social graph) with an open-source graph UI for demo—solid option, uncertain effort—skipped.
Third: rewrite parts of RocksDB with Linux’s high-performance async I/O library io_uring for TiKV gains—matched our backgrounds—chosen.

Yi Wu and Bokang competed in Beijing; I joined from Shanghai (thanks to PingCAP for remote-team approval—we were the only split team).
We read io_uring docs and targeted rewriting RocksDB WAL write and compaction. Facebook had tried io_uring for RocksDB MultiRead with ~3× random-read IOPS and lower latency—we planned a TiKV scenario to show similar wins.
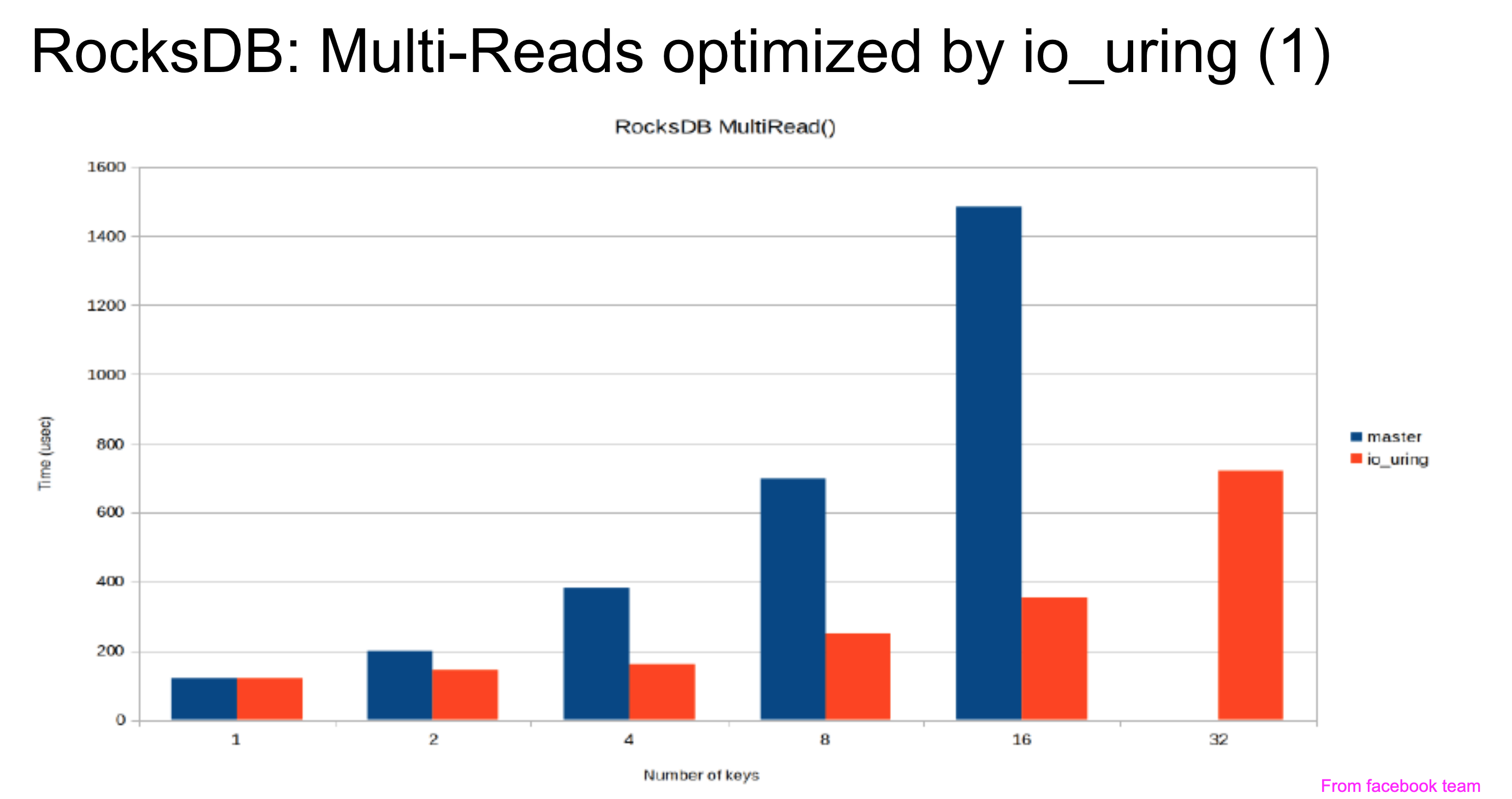
We thought performance on those three cases would be enough to argue io_uring’s value for TiDB.
Day one we finished io_uring WAL writes. Benchmarks showed no gain vs baseline—bug found. After fix, io_uring looked far faster—suspicious for write+fsync:
master: fillrandom : 77.439 micros/op 12913 ops/sec; 1.4 MB/s
uring : fillrandom : 36.503 micros/op 27394 ops/sec; 3.0 MB/s
io_uring mainly helps batched I/O; a 2× gap on single write+sync felt wrong. We reviewed code and re-read the 17-page io_uring spec, then wrote a small program to isolate io_uring vs native write+sync—io_uring was only ~10% faster, so the bug was in our RocksDB integration, not the kernel API.
We peeked at the completion queue without dequeuing—write+sync became write+write without waiting on sync, inflating bandwidth. After fixing that, RocksDB stress tests kept crashing.
We dug through RocksDB’s write path and Linux API docs without a root cause. Yi Wu recalled io_uring_prep_write(seq, fd_, iov, 1, filesize_) where iov was stack-local—freed when the function returned while async I/O still referenced it → coredump.
void run(){
int[100] iov;
//...
io_uring_prep_write(seq, fd_, iov, 1, filesize_);
//...
//end of run function()
}
After fixing lifetime, numbers looked reasonable:
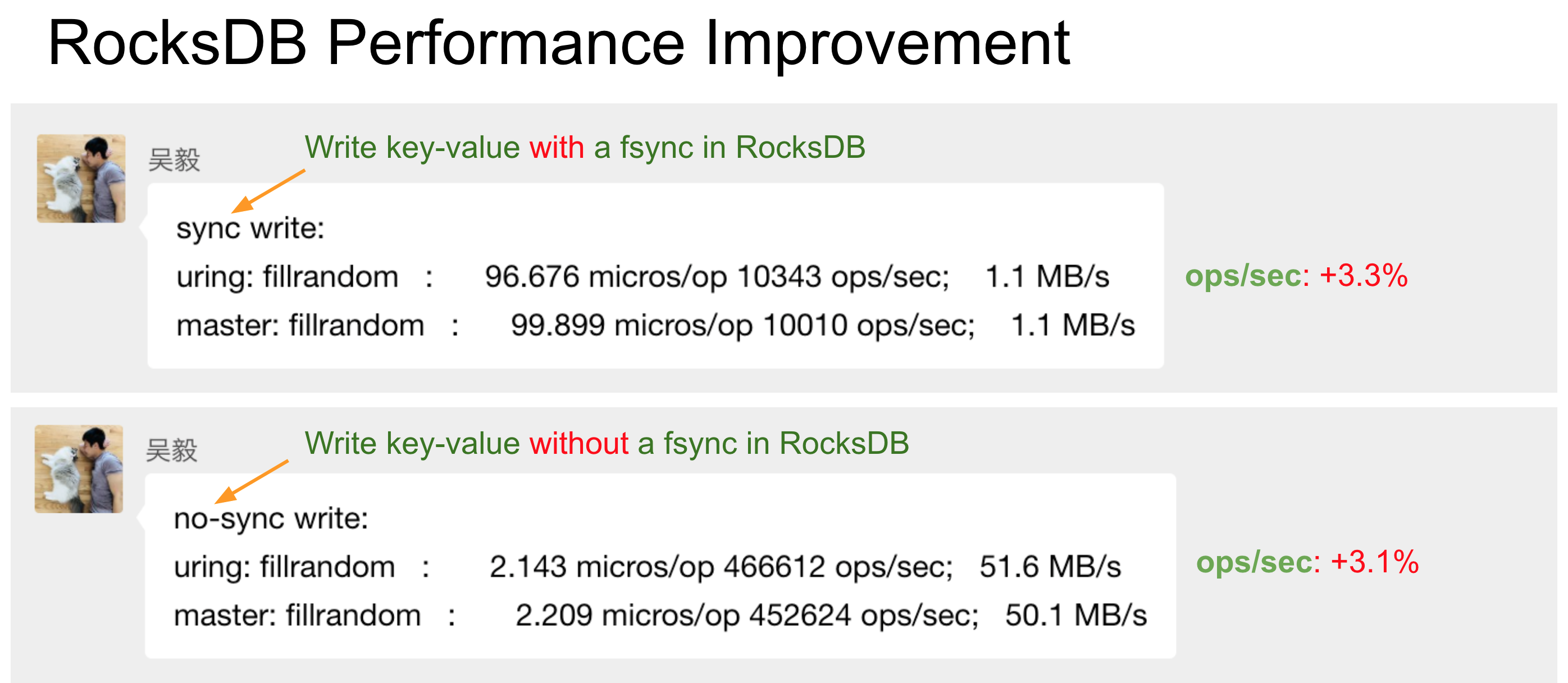
~3% ops improvement with io_uring—modest but real. Likely reasons:
Small working set, no O_DIRECT—data sat in page cache, so gain is mostly kernel-path efficiency, not bulk disk I/O. Larger data or O_DIRECT would show more.
Few async ops per batch—only write+sync were async; repeated write+sync pairs were still largely synchronous.
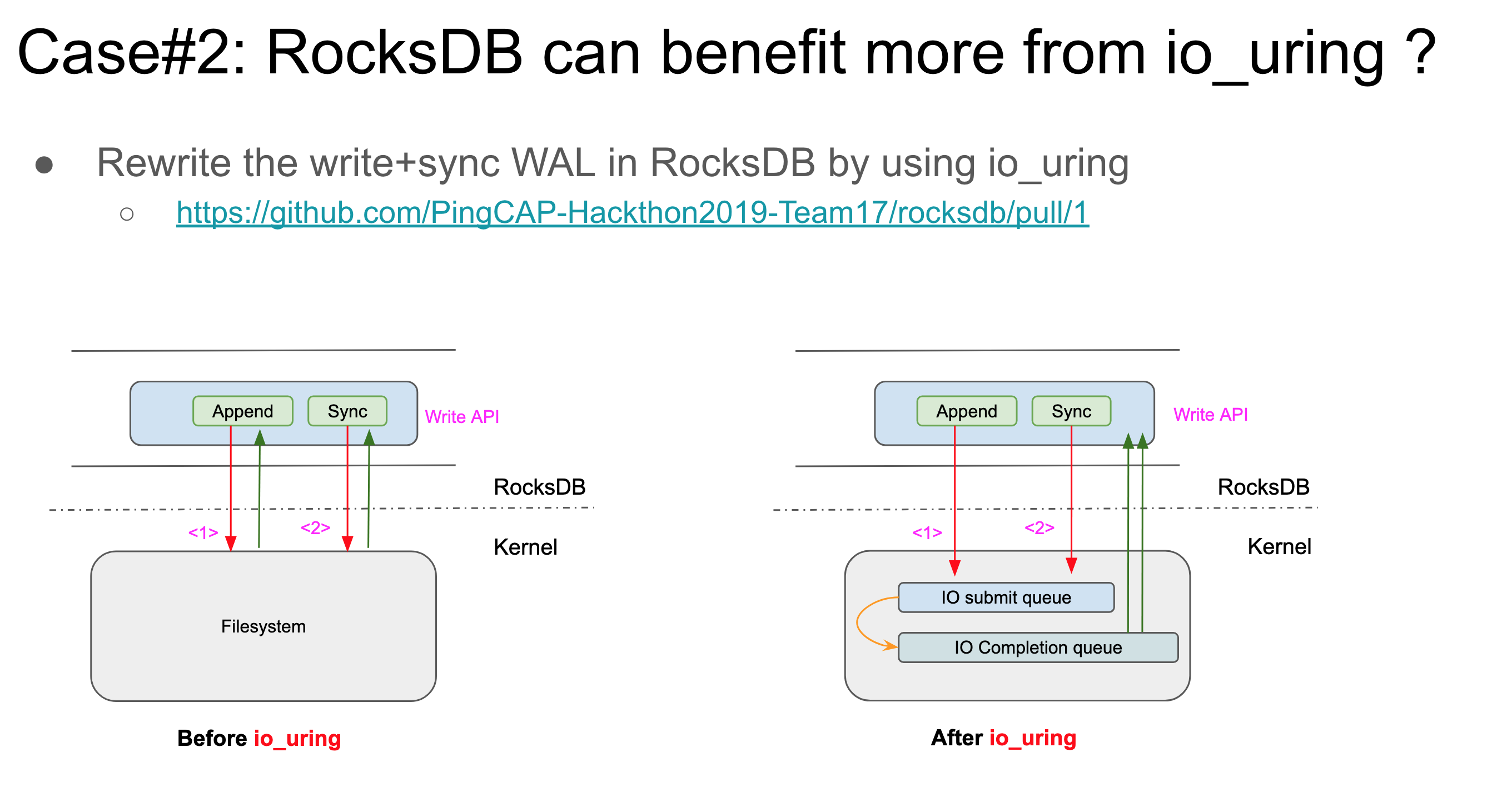
We also async-ified MultiRead and compaction with mixed gains—see our final deck.
We did not win awards, but it was solid perf engineering; TiKV may adopt io_uring as a future option—that outcome suits us.
On the event: ~80+ people and ~20 teams last year; ~120+ people and 40+ teams this year—judging ran past 9pm and many of us watched the stream on the train home. The format favors upper-stack demos. One team ran TiDB in the browser and got loud applause on show databases—I assumed they’d win big. Audience shrinks down the stack; six minutes hurts deep systems work; storage wins are slow to show. Organizers might encourage more low-level entries or hackathons may skew toward UI and application layers.
Personally I enjoyed focusing on code and debugging. Thanks to PingCAP for the platform and interesting people.