最近读了一下 Microsoft 在 2015 年 VLDB 上发表的论文 《Real-Time Analytical Processing with SQL Server》[1]。SQLServer算是业内较早实现并落地 HTAP 行列更新方案的产品,我其实觉得 行存(Row-Wise Index) 在OLTP场景下的各种设计以及取舍,大家都已经讨论的非常清楚了。对于高效率的 毫秒级列存更新 方案,业界有一些方案设计和实现,典型的如Kudu[2]、Positional Delta Tree[3] 等,但远不如行存讨论的多。我仔细的 Review 了一下 SQLServer 的技术方案,觉得他们的设计还是颇具参考意义。本文分享一下我对这篇文章的一些看法。
论文主要讲了 4 个方面的话题:
- 内存中实现列存表;
- 对于行存表,怎么实现一个列存索引结构,从而实现分析型 SQL 的极大提速。这部分的重点就是怎么实现列存二级索引的实时更新;
- 对于列存表怎么实现一个 B-Tree 的二级索引,使得这个列存表可以用来做点查和小范围扫描;
- 计算层在列存表的扫描性能上做了哪些优化。
第1部分纯内存的列存表相对比较简单,第4部分的列存表扫描在业界的很多论文中都可以找到类似的方案。第2部分和第3部分相对比较独特,可以说是整篇文章的精华,也是我比较感兴趣的部分。
其实第2部分,可以认为是在一个已经存在的OLTP表上,怎么来创建一个OLAP的列存索引,使得这个表可以跑 “TP为主,AP为辅” 的两种QUERY;而第3部分正好完全相反,相当于是在一个纯粹的OLAP列存表之上,创建一个适合做 点查 和 小范围 查询的行存索引,使得这个表可以完成 “AP为主,TP为辅” 的混合QUERY。
“TP为主,AP为辅“ 的索引方案
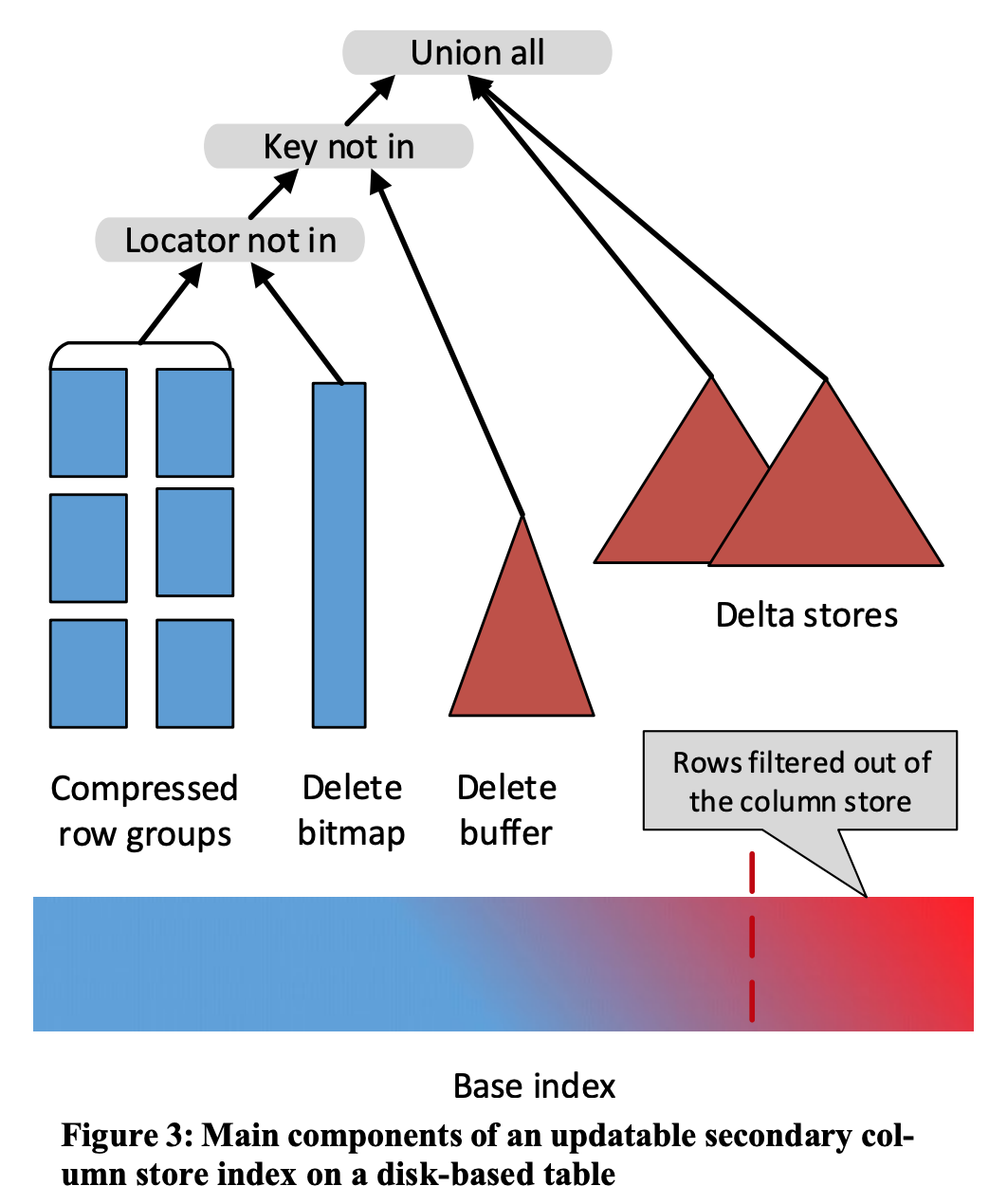
SQL Server的这种 CSI (Columnar Store Index)更新方案,说实话其实在 写入延迟 和 读取延迟 上处理的还算比较恰当。对于列存索引来说,如果是 INSERT 的话,那么直接 Append 到 Delta Store 里面就行,没啥其他的额外耗时操作;如果是 DELETE 的话,先看一下 DELETE 的 key 是否在 Delta Store 里面,如果在就直接删除即可;如果不在,就插入一条 Delete Marker 到这个由 B-Tree 索引实现的 Delete Buffer。无论是 INSERT 还是 DELETE 操作,都没有特别耗时的地方。可能往 B-Tree 索引实现的 Delete Buffer 里面写 Delete Marker 会有点儿耗时,但这个 Delete Buffer 一般都是最近更新比较热的数据。首先体量不会特别大,其次,大部分的都是热数据,都会被 Cache 到内存。然后,后台有一个任务, 会默默地把 Delete Buffer 里面的 Delete 操作都转换成 Delete Bitmap。
读取的时候,每一个 RowGroup 内的数据先要过一遍 DeleteBitMap,然后再去 Delete Buffer 中做 点查 。读取路径上,扫描可以以 RowGroup 为单位做并发扫描,对于非常大的冷数据,都可以走 DeleteBitMap 过滤掉被删除的数据,极少数的热数据,会需要做一次 key compare 的 Delete Buffer 点查,这地方会增加一些耗时。当总体来说,还是比较好地处理了读写延迟以及冷热数据的问题。简而言之,就是大体量的冷数据对耗时贡献的少一些,少量热数据对耗时贡献多一点,这使得总体来说比较平衡。
问题 1:对于大数据里面的纯列存表是否适合采用这种更新方案?
假设我现在要实现一个类似 Kudu 这种纯实时更新的列存方案,我的结论是选择用 SQL Server 这种方案是不恰当的。
首先,大数据里面的写入只有 UPSERT 和 DELETE 两种。通常意义上,大数据里面带key的 INSERT 可以认为就是 UPSERT 语义,这个语义表示如果 key 存在,那么就用覆盖掉老的值;如果这个 key 不存在,就直接插入新的值;而 UPDATE 又可以认为是先 DELETE 然后再 INSERT。那么既然大数据里面的所有写入,都是 UPSERT,这就会导致所有的写入操作都会在 Delete Buffer 中写一条行来提前删除这个row,再写一条新数据到 Delta Store。注意:这里 Delete Buffer 的体量是等价于整个大数据的写入体量。这直接导致 Delete Buffer 会非常非常的大,这就会带来一系列的副作用,例如扫描路径性能差,后台的Compaction任务压力非常大。
但是,为什么 SQL Server 没有这个问题呢?因为 SQL Server 对这个索引的定位是 “TP为主,AP为辅”,它所有的写入请求都是先走一遍 TP 的行存索引,判断这个 key 是否存在,存在的话,直接报错给用户说 duplicate key,不存在的话,就直接写 INSERT。这样落到 AP 的列存索引这边来,就全部都是语义非常确定的 INSERT 操作了,而不是 UPSERT 操作。于是,在 SQL Server 里面的 Delete Buffer 是真正的 Delete,而不是由 UPSERT 产生的大量额外 DELETE。
问题 2:能否搞定 Partial Update 的问题 ?
所谓 Partial Update,就是指定主键以及部分column值进行更新。比如一个表有(pk, a, b) 三个字段,现在要求把 pk=1 的行对应的 b 值改成 3,更新的时候不提供 a 的值。
在 SQL Server 里面同一个表既有行存 Index,又有列存 Index。所以,即使只提供了部分列的新列,其他的的列都可以从行存的 Index 中读出来。最后把这行数据的所有列的值都填上,直接写到列存 Index 中即可。
但是,如果想在一个纯列存的表内搞定 Partial Update 这个问题,挑战其实还挺大的。如果采用这种标记 Delete Bitmap 的方式,那么意味着每次写入都必须写 整行所有的列值 , 这意味着需要在列存文件中做一次整行读取,由于列存文件中同一行的每一个列都是分开存储的,做整行读取会消耗 O(n) 次 Random Seek,这个开销非常大,完全无法接受。现在我看到的较好的方案是 Apache Kudu 的方案,它每次在写入 Partial Update 的时候,直接把这个更新当作一个 Operation 记录到 Delta 内,相当于记了个 <Delete_Row_ID, Changes> 。这个 Changes 就是对应的 Operation。然后,读取的时候,需要把这个 Changes Apply 到 Delete_Row_ID 对应的 Row 上。相当于以牺牲部分读取性能的情况下,保证了写入的效率。
“AP为主,TP为辅” 的索引方案
在 SQL Server 2014 的版本中,用来做数据分析的列存表,这个表上面是没有任何 Primary Key Index 、外键约束、二级索引的。所以,这个表只能用来服务分析型查询,一旦数据分析师想要去查具体的某个整行数据时,就必须对整表做一个全表扫描,才能找出这个行。为了解决这些问题,SQL Server 在 Columnar File 之上搞了一个 B-Tree 索引,这个 B-Tree 索引维护着 <Key, Row_ID> (这里 Row_ID 等于 <Row_Group_ID, Offset_In_RowGroup> )的映射关系,这里的 Key 不一定是 Unique 的。这样用户需要根据 Key 查找整行数据的时候,就可以走一遍这个 B-Tree 定位到具体的 Row_ID (即上面说的 <Row_Group_ID, Offset_In_RowGroup> ),最后在把每个 Column 的 Value 都读出来即可。这里虽然依然是在 Columnar Store 里面做了一个点查,N 个 Column 可能产生 N 次 Random Seek,但考虑到这种请求很少,并且大部分热点数据都可以走 Cache。所以,对于 ”AP为主,TP为辅“ 的场景来说,这个索引设计基本上能满足需求。
注意,对于同一份 Columnar File,SQL Server 是可以针对不同的 Key 建立多个不同的 B-Tree 索引的。这样使得不同的 Query 可以按照不同的 Key Index 去做 Point Lookup。对各种 Query 的支持都可以做到相对来说高效的响应。
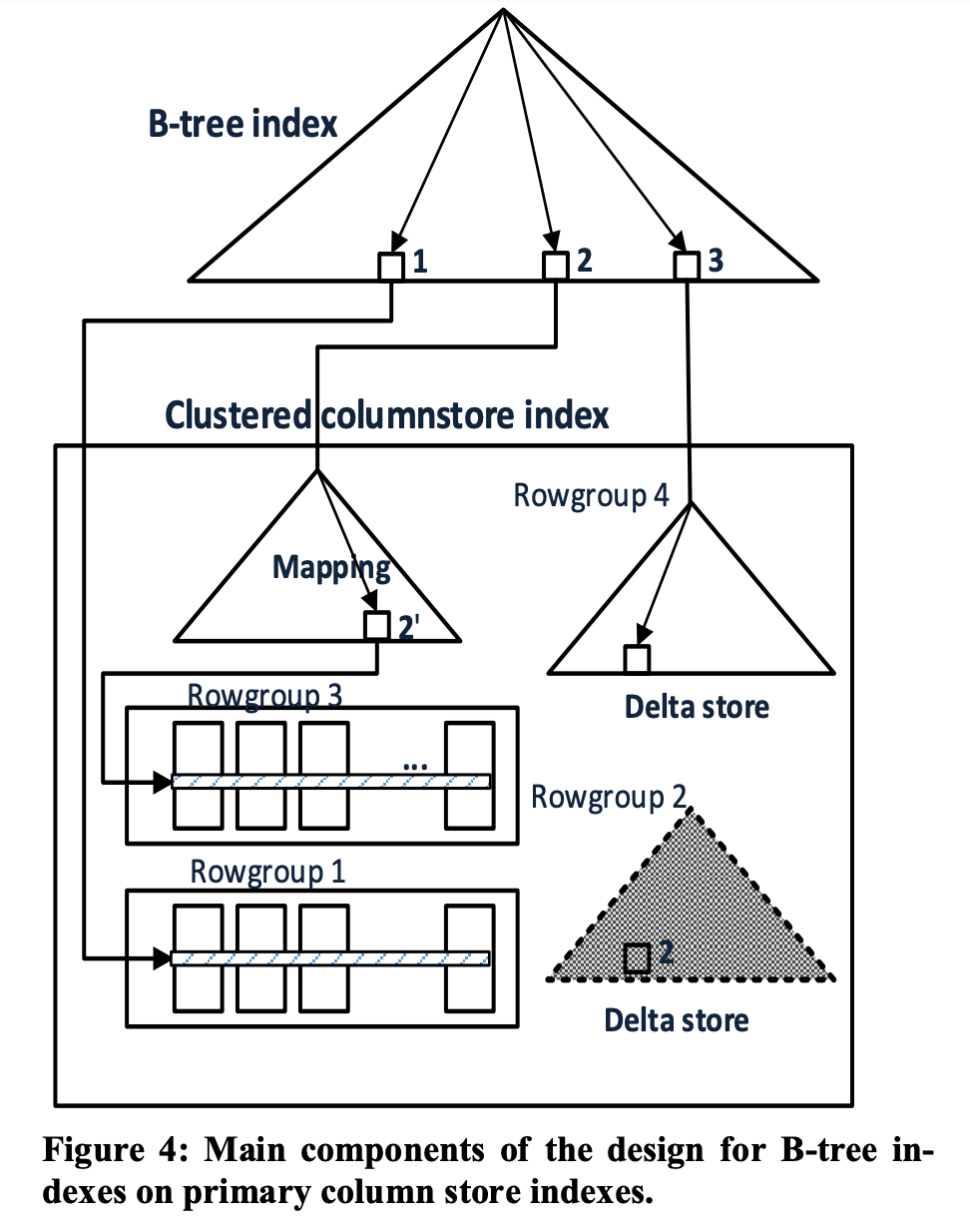
SQL Server的数据写入分两种,一种可以认为是单个 Txn 单独写入一行数据;另外一种可以认为是 Bulk Load,就是一次 Txn 写入大批量的数据。这两种写入方式,在流程上是不一样的。前者会先把单行数据写到 Delta Store 内,因为小体量的数据其实在 Cache 内攒一攒,最后一次性 Flush 到磁盘比较友好;后者是会直接开一个磁盘上的 RowGroup 做 Append 写,就不需要走 Delta Store 再 Flush 到磁盘了,因为对于大体量的数据写入,其实是没有必要来污染系统的 Cache 了。
这里有几个问题需要考虑:
问题 1:因为 Insert Row 会先走 Delta Store ,等 Delta Store 攒满一批数据之后,再 Flush 到 Columnar File 内。那么,最开始 B-Tree 中存的 <Key, Row_ID> 的这个 Row_ID 指向的是 Delta Store 中生成的 Row_ID,等 Flush 完成之后,Row_ID 就应该指向磁盘文件中的压缩后的 Row Group 的 Row_ID。这意味着所有的用 B-Tree 构建的二级索引,都需要更新这个 变动 的 RowGroup 内所有 Key 的 Row_ID。这会对整个系统产生巨大的压力。
SQL Server 的解决思路是维护了一个 Mapping Index ,这个 Mapping Index 背后也是可以 B-Tree 索引,维护着 原始 Row_ID 和 新 Row_ID 的映射关系,其中 B-Tree 里面的 Key 就是 原始 Row_ID,而 Value 就是 新 Row_ID。考虑到 Delta Store 中的每一次 RowGroup 变动,都是以 RowGroup 为单位的,所以 B-Tree 内部可以直接记录 Row_Group_ID 的映射即可,所以我认为 B-Tree 的 Key 其实可以直接是 Row_Group_ID,而不需要存 Row_ID 了。
问题 2:在 Columnar File 中做数据删除时,如何删除二级索引 B-Tree 中的信息 ?(假设不删 B-Tree 二级索引的信息,则后面的 Query 通过 B-Tree 做点查依然有会读取到已经删除的 Row )
由于 B-Tree 中记录的 Row_ID 可能是 原始 Row_ID ,而这个 原始 Row_ID 对应的 Row 可能已经经过 RowGroup Move,变成了 新的Row_ID。所以,SQL Server 设计的时候,在每一个Row中新增了一个 Column,这个 Column 用来 记录这个 Row 的原始 Row_ID,这样去 B-Tree 中做删除的时候,直接用 Key 和 原始 Row_ID 去删除即可。(注意,这里 Key 不一定 Unique,所以删除的时候一定需要明确删除同一个 Key 的具体 原始 Row_ID )。
问题 3:如何实现数据的点查 ?
可以参考上图。按以下情况分类:
- 如果通过 B-Tree 找到的 Row_ID 落在 Delta Store 内,那么直接返回即可;
- 如果通过 B-Tree 找到的 Row_ID 落在一个 Invalid 的 RowGroup上,那么需要走 Mapping Index 找到这个 Invalid Row Group 最新的 RowGroup 是啥;
- 如果通过 B-Tree 知道的 Row_ID 落在一个 Valid 的磁盘的 Row Group上,直接去这个 Row Group 查找即可。
References
[1] http://www.vldb.org/pvldb/vol8/p1740-Larson.pdf
[2] https://kudu.apache.org/kudu.pdf
[3] http://www.odbms.org/wp-content/uploads/2014/07/PositionalDelat-Trees.pdf