I recently read Microsoft’s 2015 VLDB paper, Real-Time Analytical Processing with SQL Server [1]. SQL Server was among the earlier products to ship and productionize an HTAP row/column update design. Row-store (row-wise index) tradeoffs for OLTP are well understood; efficient millisecond-scale column store updates have several designs in the wild—Kudu [2], Positional Delta Tree [3], and others—but they receive far less discussion than row stores. After a careful review of SQL Server’s approach, I find it worth sharing. This post summarizes my takeaways.
The paper covers four main topics:
- In-memory column store tables;
- For row-store tables, how to build a column store index structure that greatly speeds analytical SQL—the focus is real-time updates to a column store secondary index;
- For column store tables, how to build a B-Tree secondary index for point lookups and small range scans;
- Query-layer optimizations for scanning column store tables.
Part 1 (pure in-memory column store) is relatively straightforward; part 4 (column store scan optimizations) appears in many industry papers. Parts 2 and 3 are more distinctive—the core of the paper and what interests me most.
Part 2 is essentially: given an existing OLTP table, how to add an OLAP column store index so the table can run “TP-primary, AP-secondary” workloads. Part 3 is the mirror image: on a pure OLAP column store table, add a row-store index suited to point lookups and small range queries so the table can serve “AP-primary, TP-secondary” mixed queries.
“TP-Primary, AP-Secondary” Index Design
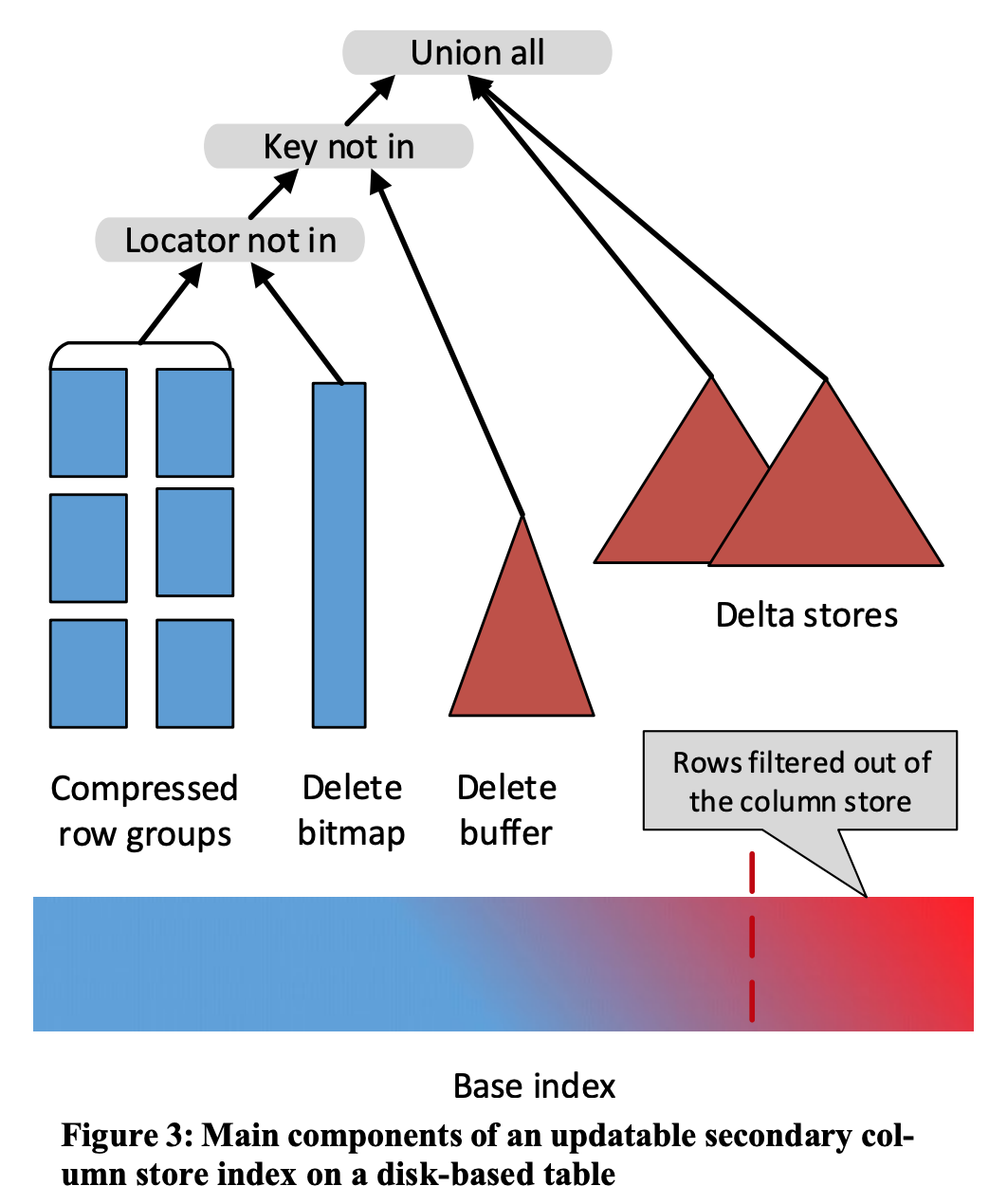
SQL Server’s CSI (Columnstore Index) update design handles write latency and read latency reasonably well. For the column store index, INSERT appends directly to the Delta Store with little extra work. DELETE first checks whether the key is in the Delta Store; if so, delete it there; otherwise insert a delete marker into the B-Tree-backed Delete Buffer. Neither INSERT nor DELETE has a particularly expensive path. Writing delete markers to the Delete Buffer may add some cost, but the Delete Buffer holds recently updated hot data—it stays relatively small and is largely cached. A background task converts Delete Buffer entries into a Delete Bitmap.
On read, each RowGroup’s data is filtered by the Delete Bitmap, then checked with a point lookup in the Delete Buffer. Scans can run concurrently per RowGroup. For large cold data, the Delete Bitmap filters deleted rows; a few hot rows need a key-compare point lookup in the Delete Buffer, adding some latency. Overall, read/write latency and hot/cold data are balanced: bulk cold data contributes less to cost; a small amount of hot data contributes more.
Question 1: Is this update design suitable for a pure column store table in big-data systems?
Suppose we want something like Kudu—a purely real-time updatable column store. I conclude SQL Server’s design is not appropriate.
In big data, writes are usually only UPSERT and DELETE. Keyed INSERT is typically UPSERT semantics: if the key exists, overwrite; if not, insert. UPDATE is effectively DELETE then INSERT. Because all writes are UPSERT-like, every write would first insert a row into the Delete Buffer to delete the old row, then write new data to the Delta Store. The Delete Buffer would grow to roughly the size of total write volume, hurting scan performance and stressing background compaction.
SQL Server avoids this because the index is “TP-primary, AP-secondary”: writes go through the TP row-store index first. If the key exists, the user gets a duplicate-key error; if not, a pure INSERT reaches the AP column store index—not UPSERT. The Delete Buffer then holds real deletes, not extra deletes from UPSERT.
Question 2: Can it handle partial updates?
A partial update specifies the primary key and only some column values—for example a table (pk, a, b) and an update that sets b = 3 for pk = 1 without supplying a.
In SQL Server the same table has both row-store and column-store indexes. Even with only partial new columns, missing columns can be read from the row-store index, the full row assembled, and written to the column store index.
On a pure column store table, partial update is much harder. With a delete-bitmap style design, each write must supply all column values for the row, requiring a full-row read from column files. Columns of one row are stored separately, so a full-row read costs O(n) random seeks—usually unacceptable. A better approach seen in Apache Kudu records each partial update as an operation in the delta: <Delete_Row_ID, Changes>. On read, Changes is applied to the row at Delete_Row_ID, trading some read cost for write efficiency.
“AP-Primary, TP-Secondary” Index Design
In SQL Server 2014, analytical column store tables had no primary key index, foreign keys, or secondary indexes—only analytical queries. Point lookups on a specific row required a full table scan. To fix that, SQL Server added a B-Tree index on top of the columnar file maintaining <Key, Row_ID> mappings (Row_ID = <Row_Group_ID, Offset_In_RowGroup>). Keys need not be unique. A key lookup walks the B-Tree to a Row_ID, then reads each column’s value from the column store. That still implies up to N random seeks for N columns, but such requests are rare and hot data is cached—acceptable for “AP-primary, TP-secondary” workloads.
Note: SQL Server can build multiple B-Tree indexes on different keys over the same columnar file, so different queries can use different key indexes for efficient point lookups.
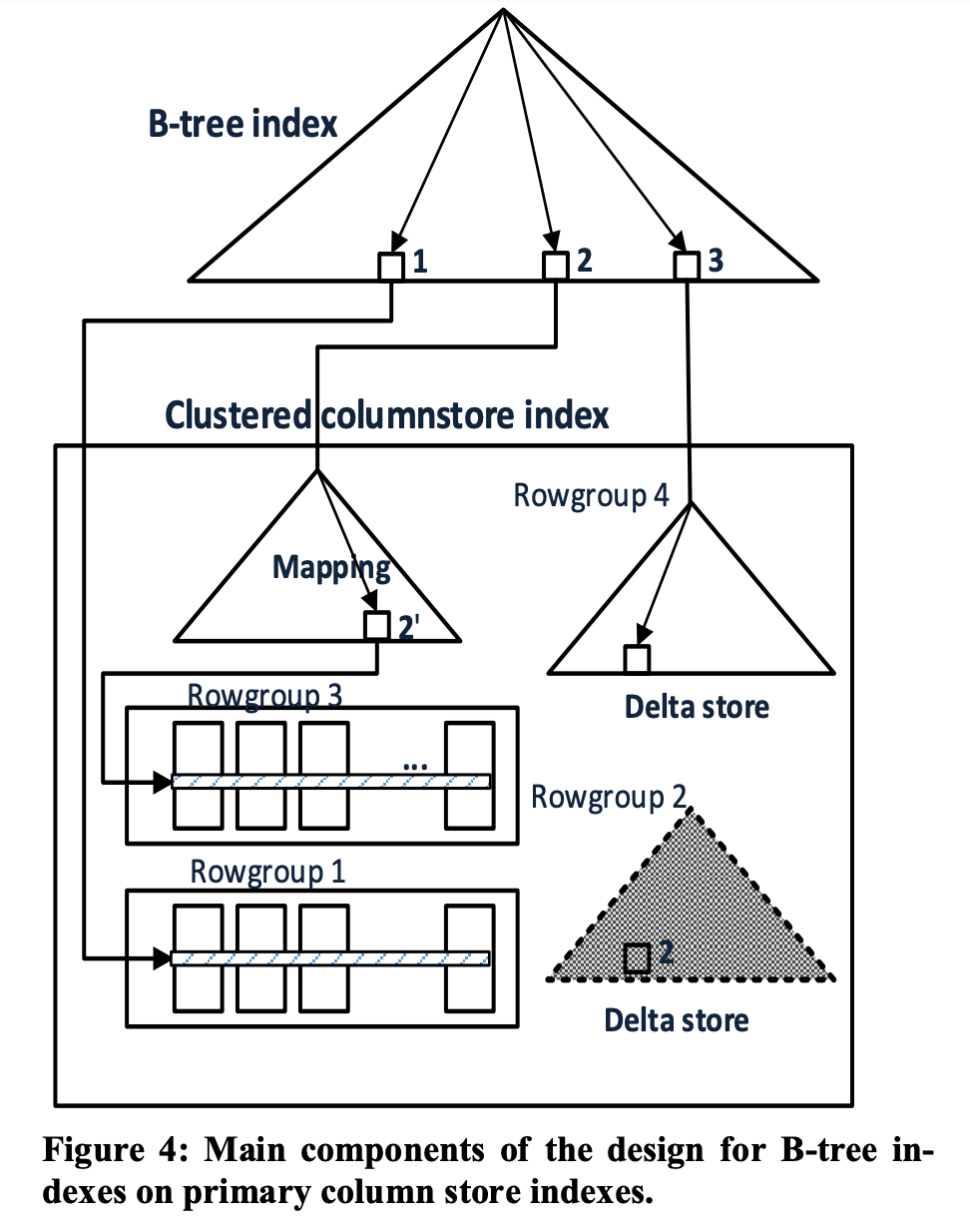
SQL Server has two write paths: single-row writes in one transaction, and bulk load of large batches. Single-row inserts go to the Delta Store first—small batches are friendlier to cache before a flush to disk. Bulk load appends directly to an on-disk RowGroup, skipping the Delta Store, because large writes should not pollute the cache.
Several design questions arise:
Question 1: Single-row inserts go to the Delta Store; when the Delta Store fills, data flushes to the columnar file. Initially the B-Tree’s <Key, Row_ID> Row_ID points at Delta Store Row_IDs; after flush, Row_IDs must point at compressed RowGroups on disk. Every B-Tree secondary index must update Row_IDs for all keys in the moved RowGroup—potentially huge pressure.
SQL Server’s answer is a Mapping Index—also B-Tree-backed—mapping original Row_ID to new Row_ID. Because Delta Store moves happen per RowGroup, the B-Tree can record Row_Group_ID mappings; the key can be Row_Group_ID rather than full Row_ID.
Question 2: When deleting data in the columnar file, how do we remove entries from the B-Tree secondary index? (Without removal, point lookups via the B-Tree could still return deleted rows.)
B-Tree Row_IDs may be original Row_IDs whose rows have moved to new Row_IDs via RowGroup moves. SQL Server adds a column on each row recording that row’s original Row_ID. Deletes from the B-Tree use Key plus original Row_ID (keys may not be unique, so the specific original Row_ID must be specified).
Question 3: How are point lookups implemented?
See the figure above. Cases:
- If the B-Tree Row_ID falls in the Delta Store, return the row directly;
- If it falls on an invalid RowGroup, use the Mapping Index to find the latest valid RowGroup;
- If it falls on a valid on-disk RowGroup, read from that RowGroup directly.
References
[1] http://www.vldb.org/pvldb/vol8/p1740-Larson.pdf
[2] https://kudu.apache.org/kudu.pdf
[3] http://www.odbms.org/wp-content/uploads/2014/07/PositionalDelat-Trees.pdf